Уровень значимости в статистике
Уровень значимости в статистике является важным показателем, отражающим степень уверенности в точности, истинности полученных (прогнозируемых) данных. Понятие широко применяется в различных сферах: от проведения социологических исследований, до статистического тестирования научных гипотез.

Определение
Уровень статистической значимости (или статистически значимый результат) показывает, какова вероятность случайного возникновения исследуемых показателей. Общая статистическая значимость явления выражается коэффициентом р-value (p-уровень). В любом эксперименте или наблюдении существует вероятность, что полученные данные возникли из-за ошибок выборки. Особенно это актуально для социологии.
То есть статистически значимой является величина, чья вероятность случайного возникновения крайне мала либо стремится к крайности. Крайностью в этом контексте считают степень отклонения статистики от нуль-гипотезы (гипотезы, которую проверяют на согласованность с полученными выборочными данными). В научной практике уровень значимости выбирается перед сбором данных и, как правило, его коэффициент составляет 0,05 (5 %). Для систем, где крайне важны точные значения, этот показатель может составлять 0,01 (1 %) и менее.
История вопроса
Понятие уровня значимости было введено британским статистиком и генетиком Рональдом Фишером в 1925 году, когда он разрабатывал методику проверки статистических гипотез. При анализе какого-либо процесса существует определенная вероятность тех либо иных явлений. Трудности возникают при работе с небольшими (либо не очевидными) процентами вероятностей, подпадающими под понятие «погрешность измерений».
При работе со статистическими данными, недостаточно конкретными, чтобы их проверить, ученые сталкивались с проблемой нулевой гипотезы, которая «мешает» оперировать малыми величинами. Фишер предложил для таких систем определить вероятность событий в 5 % (0,05) в качестве удобного выборочного среза, позволяющего отклонить нуль-гипотезу при расчетах.
Введение фиксированного коэффициента
В 1933 году ученые Ежи Нейман и Эгон Пирсон в своих работах рекомендовали заранее (до сбора данных) устанавливать определенный уровень значимости. Примеры использования этих правил хорошо видны во время проведения выборов. Предположим, есть два кандидата, один из которых очень популярен, а второй – малоизвестен. Очевидно, что первый кандидат выборы выиграет, а шансы второго стремятся к нулю. Стремятся – но не равны: всегда есть вероятность форс-мажорных обстоятельств, сенсационной информации, неожиданных решений, которые могут изменить прогнозируемые результаты выборов.
Нейман и Пирсон согласились, что предложенный Фишером уровень значимости 0,05 (обозначаемый символом α) наиболее удобен. Однако сам Фишер в 1956 году выступил против фиксации этого значения. Он считал, что уровень α должен устанавливаться в соответствии с конкретными обстоятельствами. Например, в физике частиц он составляет 0,01.
Значение p-уровня
Термин р-value впервые использован в работах Браунли в 1960 году. P-уровень (p-значение) является показателем, находящимся в обратной зависимости от истинности результатов. Наивысший коэффициент р-value соответствует наименьшему уровню доверия к произведенной выборке зависимости между переменными.
Данное значение отражает вероятность ошибок, связанных с интерпретацией результатов. Предположим, p-уровень = 0,05 (1/20). Он показывает пятипроцентную вероятность того, что найденная в выборке связь между переменными – всего лишь случайная особенность проведенной выборки. То есть, если эта зависимость отсутствует, то при многократных подобных экспериментах в среднем в каждом двадцатом исследовании можно ожидать такую же либо большую зависимость между переменными. Часто p-уровень рассматривается в качестве «допустимой границы» уровня ошибок.
Кстати, р-value может не отражать реальную зависимость между переменными, а лишь показывает некое среднее значение в пределах допущений. В частности, окончательный анализ данных будет также зависеть от выбранных значений данного коэффициента. При p-уровне = 0,05 будут одни результаты, а при коэффициенте, равном 0,01, другие.
Проверка статистических гипотез
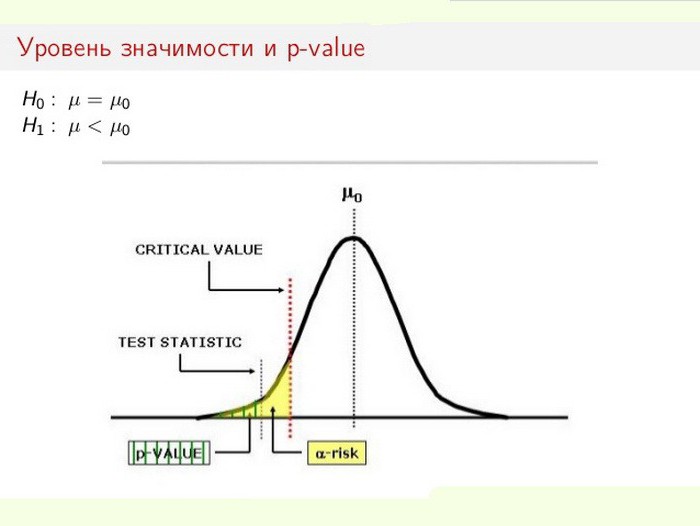
Уровень статистической значимости особенно важен при проверке выдвигаемых гипотез. Например, при расчетах двустороннего теста область отторжения разделяют поровну на обоих концах выборочного распределения (относительно нулевой координаты) и высчитывают истинность полученных данных.
Предположим, при мониторинге некоего процесса (явления) выяснилось, что новая статистическая информация свидетельствует о небольших изменениях относительно предыдущих значений. При этом расхождения в результатах малы, не очевидны, но важны для исследования. Перед специалистом встает дилемма: изменения реально происходят или это ошибки выборки (неточность измерений)?
Эффективность
Необходимо учитывать, что коэффициенты α и р-value не являются точными характеристиками. Каким бы ни был уровень значимости в статистике исследуемого явления, он не является безусловным основанием для принятия гипотезы. Например, чем меньше значение α, тем больше шанс, что устанавливаемая гипотеза значима. Однако существует риск ошибиться, что уменьшает статистическую мощность (значимость) исследования.
Исследователи, которые зацикливаются исключительно на статистически значимых результатах, могут получить ошибочные выводы. При этом перепроверить их работу затруднительно, так как ими применяются допущения (коими фактически и являются значения α и р-value). Поэтому рекомендуется всегда, наряду с вычислением статистической значимости, определять другой показатель – величину статистического эффекта. Величина эффекта – это количественная мера силы эффекта.
Уровень статистической значимости (р)
В таблицах результатов статистических расчётов в курсовых, дипломных и магистерских работах по психологии всегда присутствует показатель «р».
Например, в соответствии с задачами исследования были рассчитаны различия уровня осмысленности жизни у мальчиков и девочек подросткового возраста.
Уровень статистической значимости (p)
В правом столбце указано значение «р» и именно по его величине можно определить значимы различия осмысленности жизни в будущем у мальчиков и девочек или не значимы. Правило простое:
Откуда берется уровень статистической значимости «р»
Уровень статистической значимости вычисляется статистической программой вместе с расчётом статистического критерия. В этих программах можно также задать критическую границу уровня статистической значимости и соответствующие показатели будут выделяться программой.
Например, в программе STATISTICA при расчете корреляций можно установить границу «р», например, 0,05 и все статистически значимые взаимосвязи будут выделены красным цветом.
Если расчёт статистического критерия проводится вручную, то уровень значимости «р» выявляется путем сравнения значения полученного критерия с критическим значением.
Что показывает уровень статистической значимости «р»
Все статистические расчеты носят приблизительный характер. Уровень этой приблизительности и определяет «р». Уровень значимости записывается в виде десятичных дробей, например, 0,023 или 0,965. Если умножить такое число на 100, то получим показатель р в процентах: 2,3% и 96,5%. Эти проценты отражают вероятность ошибочности нашего предположения о взаимосвязи, например, между агрессивностью и тревожностью.
То есть, коэффициент корреляции 0,58 между агрессивностью и тревожностью получен при уровне статистической значимости 0,05 или вероятности ошибки 5%. Что это конкретно означает?
Выявленная нами корреляция означает, что в нашей выборке наблюдается такая закономерность: чем выше агрессивность, тем выше тревожность. То есть, если мы возьмем двух подростков, и у одного тревожность будет выше, чем у другого, то, зная о положительной корреляции, мы можем утверждать, что у этого подростка и агрессивность будет выше. Но так как в статистике все приблизительно, то, утверждая это, мы допускаем, что можем ошибиться, причем вероятность ошибки 5%. То есть, сделав 20 таких сравнений в этой группе подростков, мы можем 1 раз ошибиться с прогнозом об уровне агрессивности, зная тревожность.
Какой уровень статистической значимости лучше: 0,01 или 0,05
Уровень статистической значимости отражает вероятность ошибки. Следовательно, результат при р=0,01 более точный, чем при р=0,05.
В психологических исследованиях приняты два допустимых уровня статистической значимости результатов:
р=0,01 – высокая достоверность результата сравнительного анализа или анализа взаимосвязей;
р=0,05 – достаточная точность.
Надеюсь, эта статья поможет вам написать работу по психологии самостоятельно. Если понадобится помощь, обращайтесь (все виды работ по психологии; статистические расчеты). Заказать
Уровни статистической значимости
Результаты математической обработки данных почти любым методом в конечном итоге оцениваются по уровню статистической значимости полученного результата. Это может быть уровень значимости коэффициента корреляции (Пирсона, Спирмена), уровень значимости различий по результатам сравнения выборок по тому или иному статистическому критерию (Стьюдента, Манна-Уитни, Вилкоксона, Хи-квадрат) и т.п. — вне зависимости от используемого метода, уровни значимости оцениваются одинаково.
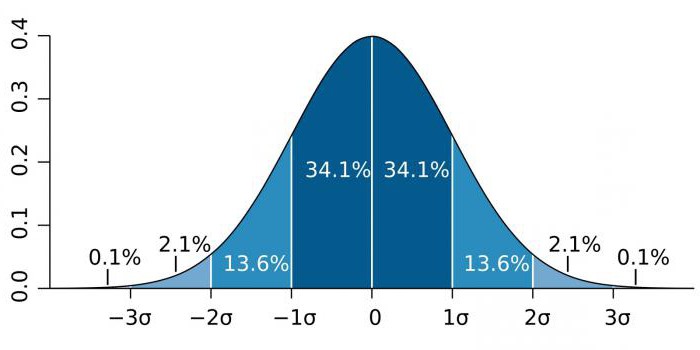
Уровень статистической значимости обозначается латинской буквой p. Традиционно выделяют три уровня статистической значимости результатов математической обработки данных:
Кроме того, иногда в результатах исследований выделяют и описывают также близкие к статистически значимым результаты (p≈0,05). Сюда можно отнести такие показатели статистической значимости, как 0,06, 0,07, 0,08 и 0,09. Они свидетельствуют о наличии тенденции к существованию соответствующей закономерности.
Что касается показателей статистической значимости величиной от 0,1 и выше — они говорят о том, что полученный результат не является статистически значимым. Например, если речь идет о сравнении выборок, то подобный показатель свидетельствует об отсутствии статистически значимых различий между сравниваемыми выборками.
По сути уровень статистической значимости отражает вероятность ошибки в выявлении закономерности. Поэтому чем меньше величина показателя p, тем ниже вероятность ошибки, тем более статистически значимым является полученный результат.
Уровни значимости критерия
Уровень значимости – вероятность ошибочного отклонения (отвержения) гипотезы, в то время как она на самом деле верна. Речь идет об отклонении нулевой гипотезы.
1. 1-й уровень значимости: α ≤ 0,05.
Это 5%-ный уровень значимости. До 5% составляет вероятность того, что мы ошибочно сделали вывод о том, что различия достоверны, в то время как они недостоверны на самом деле. Можно сказать и по-другому: мы лишь на 95% уверены в том, что различия действительно достоверны.
2. 2-й уровень значимости: α ≤ 0,01.
Это 1%-ный уровень значимости. Вероятность ошибочного вывода о том, что различия достоверны, составляет не более 1%. Можно сказать и по-другому: мы на 99% уверены в том, что различия действительно достоверны.
3. 3-й уровень значимости: α ≤ 0,001.
В области ФК и спорта достаточен уровень значимости α = 0,05, более серьезные выводы рекомендуется давать, используя уровень значимости α = 0,01 или α = 0,001.
7.2. F- критерий Фишера
Пример 4. В экспериментальной группе школьников средний прирост результатов в прыжках в длину с разбега, после применения новой методики обучения, составил 10 см (  10 см). В контрольной группе, где применялось традиционная методика, 4 см (
10 см). В контрольной группе, где применялось традиционная методика, 4 см (  4 см). Исходные данные:
4 см). Исходные данные:
Экспериментальная группа (xi): 17; 11; 3; 8; 9; 12; 10; 13; 10; 7.
Контрольная группа (yi): 8; 1; 6; 2; 3; 0; 4; 7; 5; 4.
Можно ли утверждать, что нововведения эффективнее повлияли на процесс формирования изучаемого двигательного действия по сравнению с традиционной методикой?
1) Задаемся уровнем значимости α = 0,05.
2) Вычисляем исправленные выборочные дисперсии из нашего примера по формуле:



4) Из таблицы 3 приложения при α =0,05; df1 = n1 – 1 = 9; df2 = n2 – 1 = 9; находим F0,05 = 3,18
5) Сравниваем между собой значения F и F0,05.
Вывод. Поскольку F
Общее название для класса методов статистической проверки гипотез (статистических критериев), основанных на распределении Стьюдента. Наиболее частые случаи применения t-критерия связаны с проверкой равенства средних значений в двух выборках. t-статистика строится обычно по следующему общему принципу: в числителе случайная величина с нулевым математическим ожиданием (при выполнении нулевой гипотезы), а в знаменателе — выборочное стандартное отклонение этой случайной величины, получаемое как квадратный корень из несмещенной оценки дисперсии.
Устанавливает доказательство достоверного различия или, наоборот, отсутствие различия в двух выборочных средних значениях для независимых выборок. Рассмотрим последовательность вычислений, используя пример 4:
1) Принимаем предположение о нормальности распределения генеральных совокупностей, из которых получены данные. Формулируем гипотезы:
Нулевая гипотеза Ho:  =
=  .
.
Альтернативная гипотеза: H1: ≠ .
Задаемся уровнем значимости α = 0,05.
2) В результате предварительной проверки при использовании критерия Фишера установлено, что различие дисперсий статистически недостоверно: D(x) = D(y).
3) Так как генеральные дисперсии D(x) и D(y) одинаковы, а n1 и n2 – объёмы малых независимых выборок, то наблюдаемое значение критерия равно:


Вычисляем число степеней свободы по формуле

Нулевая гипотеза отвергается, если │  │ ˃
│ ˃  , Из таблицы 1 приложения находим критическое значение t – критерия при α = 0,05;
, Из таблицы 1 приложения находим критическое значение t – критерия при α = 0,05;  =18:
=18:  = 2,101
= 2,101
Вывод: поскольку >  (4,18 ˃ 2,101), то на уровне значимости 0,05 мы отвергаем гипотезу Н0 и принимаем альтернативную гипотезу Н1.
(4,18 ˃ 2,101), то на уровне значимости 0,05 мы отвергаем гипотезу Н0 и принимаем альтернативную гипотезу Н1.
Таким образом, нововведения успешнее решают задачу обучения школьников прыжкам в длину с разбега, чем традиционная методика.
Далее рассмотрим сравнение двух выборочных средних значений для связанных выборок (парное сравнение).
Условия применения  – разность связанных пар результатов измерения. Делается предположение о нормальном распределении этих разностей в генеральной совокупности с параметрами
– разность связанных пар результатов измерения. Делается предположение о нормальном распределении этих разностей в генеральной совокупности с параметрами  .
.
Пример 5. Группа 10 школьников в течение летних каникул находилась в летнем оздоровительном лагере. До и после сезона у них измеряли жизненную емкость легких (ЖЕЛ). По результатам измерений нужно определить, достоверно ли изменился этот показатель под влиянием физических упражнений на свежем воздухе.
Исходные данные до эксперимента (xi; мл) 3400; 3600; 3000; 3500; 2900; 3100; 3200; 3400; 3200; 3400, т.е. объем выборки n = 10.
После эксперимента (yi; мл): 3800; 3700; 3300; 3600; 3100; 3200; 3200; 3300; 3500; 3600.
1) Находим разность связанных пар результатов измерения di:
;


2) Формулируем гипотезы:
Нулевая гипотеза Ho:  =
= 
Альтернативная гипотеза: H1: ≠ 0.
3) Задаемся уровнем значимости α = 0,05
5) Значение t- критерия определяем по формуле для связанных пар:

Из таблицы 1 приложения находим критическое значение t – критерия при α = 0,05; = n – 1 = 9: = 2,262
Вывод:Поскольку t > tкр (3,36 > 2,262)наблюдаемое различие по показателю ЖЕЛ является статистически достоверным на уровне значимости α=0,05.
СПИСОК РЕКОМЕНДУЕМОЙ ЛИТЕРАТУРЫ
1. Афанасьев В.В. Основы отбора, за и контроля в спорте / В.В. Афанасьев, А.В. Муравьев, И.А. Осетров. – Ярославль: Изд-во ЯГПУ, 2008. − 278 с.
2. Биленко, А.Г. Основы спортивной метрологии: Учебное пособие /А.Г. Биленко, Л.П. Говорков; СПб ГУФК им. П.Ф. Лесгафта. – СПб., 2005. – 138 с.
3. Губа В.П. Измерения и вычисления в спортивно- педагогической практике: учебное пособие для студентов высших учебных заведений/ В.П. Губа, М.П.Шестаков, Н.Б. Бубнов, М.П. Борисенков. – М.: ФиС, 2006. – 220 с.
5. Коренберг, В.Б. Спортивная метрология: учебник / В.Б. Коренберг – М.: Физическая культура, 2008. – 368 с.
6. Начинская, С. В. Спортивная метрология. Учебное пособие для студ. высш. учеб. заведений / С. В. Начинская.– М.: Издательский центр «Академия», 2005. – 240 с.
7. Начинская С.В. Применение статистических методов в сфере физической культуры / Начинская С.В – СПб., 2000. – 260 с.
8. Смирнов, Ю. И. Спортивная метрология: учеб. для студ. пед. вузов / Ю. И Смирнов, М. М. Полевщиков. – М.: Издат. центр «Академия», 2000. – 232 с.
На что мы обращаем внимание при расчете статистической значимости A/B-теста
В Учи.ру мы стараемся даже небольшие улучшения выкатывать A/B-тестом, только за этот учебный год их было больше 250. A/B-тест — мощнейший инструмент тестирования изменений, без которого сложно представить нормальное развитие интернет-продукта. В то же время, несмотря на кажущуюся простоту, при проведении A/B-теста можно допустить серьёзные ошибки как на этапе дизайна эксперимента, так и при подведении итогов. В этой статье я расскажу о некоторых технических моментах проведения теста: как мы определяем срок тестирования, подводим итоги и как избегаем ошибочных результатов при досрочном завершении тестов и при тестировании сразу нескольких гипотез. 
Типичная схема A/B-тестирования у нас (да и у многих) выглядит так:
Статистическая значимость, критерии и ошибки
В любом A/B-тесте присутствует элемент случайности: метрики групп зависят не только от их функционала, но и от того, какие пользователи в них попали и как они себя ведут. Чтобы достоверно сделать выводы о превосходстве какой-то группы, нужно набрать достаточно наблюдений в тесте, но даже тогда вы не застрахованы от ошибок. Их различают два типа:
Самый распространенный параметрический тест — критерий Стьюдента. Для двух независимых выборок (случай A/B-теста) его иногда называют критерием Уэлча. Этот критерий работает корректно, если исследуемые величины распределены нормально. Может показаться, что на реальных данных это требование почти никогда не удовлетворяется, однако на самом деле тест требует нормального распределения выборочных средних, а не самих выборок. На практике это означает, что критерий можно применять, если у вас в тесте достаточно много наблюдений (десятки-сотни) и в распределениях нет совсем уж длинных хвостов. При этом характер распределения исходных наблюдений неважен. Читатель самостоятельно может убедиться, что критерий Стьюдента работает корректно даже на выборках, сгенерированных из распределений Бернулли или экспоненциального.
Из непараметрических критериев популярен критерий Манна — Уитни. Его стоит применять, если ваши выборки очень малого размера или есть большие выбросы (метод сравнивает медианы, поэтому устойчив к выбросам). Также для корректной работы критерия в выборках должно быть мало совпадающих значений. На практике нам ни разу не приходилось применять непараметрические критерии, в своих тестах всегда пользуемся критерием Стьюдента.
Проблема множественного тестирования гипотез

Например, для трёх экспериментальных групп получим 14.3% вместо ожидаемых 5%. Решается проблема поправкой Бонферрони на множественную проверку гипотез: нужно просто поделить уровень значимости на количество сравнений (то есть групп) и работать с ним. Для примера выше уровень значимости с учётом поправки составит 0.05/3 = 0.0167 и вероятность хотя бы одной ошибки первого рода составит приемлемые 4.9%.

P-value первой гипотезы сравнивается с уровнем статистический значимости  . Если гипотеза принимается, то переходим ко второй и сравниваем её p-value с уровнем статистической значимости
. Если гипотеза принимается, то переходим ко второй и сравниваем её p-value с уровнем статистической значимости  , и так далее. Как только какая-то гипотеза отвергается, процесс останавливается и все оставшиеся гипотезы так же отвергаются. Самое жёсткое требование (и такое же, как в поправке Бонферрони) накладывается на гипотезу с наименьшим p-value, а большая мощность достигается за счёт менее жёстких условий для последующих гипотез. Цель A/B-теста — выбрать одного единственного победителя, поэтому методы Бонферрони и Холма — Бонферрони абсолютно идентичны в этом приложении.
, и так далее. Как только какая-то гипотеза отвергается, процесс останавливается и все оставшиеся гипотезы так же отвергаются. Самое жёсткое требование (и такое же, как в поправке Бонферрони) накладывается на гипотезу с наименьшим p-value, а большая мощность достигается за счёт менее жёстких условий для последующих гипотез. Цель A/B-теста — выбрать одного единственного победителя, поэтому методы Бонферрони и Холма — Бонферрони абсолютно идентичны в этом приложении.
Строго говоря, сравнения групп по разным метрикам или срезам аудитории тоже подвержены проблеме множественного тестирования. Формально учесть все проверки довольно сложно, потому что их количество сложно спрогнозировать заранее и подчас они не являются независимыми (особенно если речь идёт про разные метрики, а не срезы). Универсального рецепта нет, полагайтесь на здравый смысл и помните, что если проверить достаточно много срезов по разным метрикам, то в любом тесте можно увидеть якобы статистически значимый результат. А значит, надо с осторожностью относиться, например, к значимому приросту ретеншена пятого дня новых мобильных пользователей из крупных городов.
Проблема подглядывания
Частный случай множественного тестирования гипотез — проблема подглядывания (peeking problem). Смысл в том, что значение p-value по ходу теста может случайно опускаться ниже принятого уровня значимости. Если внимательно следить за экспериментом, то можно поймать такой момент и ошибочно сделать вывод о статистической значимости.
Предположим, что мы отошли от описанной в начале поста схемы проведения тестов и решили подводить итоги на уровне значимости 5% каждый день (или просто больше одного раза за время теста). Под подведением итогов я понимаю признание теста положительным, если p-value ниже 0.05, и его продолжение в противном случае. При такой стратегии доля ложноположительных результатов будет пропорциональна количеству проверок и уже за первый месяц достигнет 28%. Такая огромная разница кажется контринтуитивной, поэтому обратимся к методике A/A-тестов, незаменимой для разработки схем A/B-тестирования.
Идея A/A-теста проста: симулировать на исторических данных много A/B-тестов со случайным разбиением на группы. Разницы между группами заведомо нет, поэтому можно точно оценить долю ошибок первого рода в своей схеме A/B-тестирования. На гифке ниже показано, как изменяются значения p-value по дням для четырёх таких тестов. Равный 0.05 уровень значимости обозначен пунктирной линией. Когда p-value опускается ниже, мы окрашиваем график теста в красный. Если бы в этом время подводились итоги теста, он был бы признан успешным.
Рассчитаем аналогично 10 тысяч A/A-тестов продолжительностью в один месяц и сравним доли ложноположительных результатов в схеме с подведением итогов в конце срока и каждый день. Для наглядности приведём графики блуждания p-value по дням для первых 100 симуляций. Каждая линия — p-value одного теста, красным выделены траектории тестов, в итоге ошибочно признанных удачными (чем меньше, тем лучше), пунктирная линия — требуемое значение p-value для признания теста успешным.
На графике можно насчитать 7 ложноположительных тестов, а всего среди 10 тысяч их было 502, или 5%. Хочется отметить, что p-value многих тестов по ходу наблюдений опускались ниже 0.05, но к концу наблюдений выходили за пределы уровня значимости. Теперь оценим схему тестирования с подведением итогов каждый день:
Красных линий настолько много, что уже ничего не понятно. Перерисуем, обрывая линии тестов, как только их p-value достигнут критического значения:
Всего будет 2813 ложноположительных тестов из 10 тысяч, или 28%. Понятно, что такая схема нежизнеспособна.
Хоть проблема подглядывания — это частный случай множественного тестирования, применять стандартные поправки (Бонферрони и другие) здесь не стоит, потому что они окажутся излишне консервативными. На графике ниже — доля ложноположительных результатов в зависимости от количества тестируемых групп (красная линия) и количества подглядываний (зелёная линия).
Хотя на бесконечности и в подглядываниях мы вплотную приблизимся к 1, доля ошибок растёт гораздо медленнее. Это объясняется тем, что сравнения в этом случае независимыми уже не являются.
Методы досрочного завершения теста
Есть варианты тестирования, позволяющие досрочно принять тест. Расскажу о двух из них: с постоянным уровнем значимости (поправка Pocock’a) и зависимым от номера подглядывания (поправка O’Brien-Fleming’a). Строго говоря, для обеих поправок нужно заранее знать максимальный срок теста и количество проверок между запуском и окончанием теста. Причём проверки должны происходить примерно через равные промежутки времени (или через равные количества наблюдений).
Pocock
Метод заключается в том, что мы подводим итоги тестов каждый день, но при сниженном (более строгом) уровне значимости. Например, если мы знаем, что сделаем не больше 30 проверок, то уровень значимости надо выставить равным 0.006 (подбирается в зависимости от количества подглядываний методом Монте-Карло, то есть эмпирически). На нашей симуляции получим 4% ложноположительных исходов — видимо, порог можно было увеличить.
Несмотря на кажущуюся наивность, некоторые крупные компании пользуются именно этим способом. Он очень прост и надёжен, если вы принимаете решения по чувствительным метрикам и на большом трафике. Например, в «Авито» по умолчанию уровень значимости принят за 0.005.
O’Brien-Fleming

Соответствующие уровни значимости вычисляются через перцентиль  стандартного распределения, соответствующий значению статистики Стьюдента
стандартного распределения, соответствующий значению статистики Стьюдента  :
:
На тех же симуляциях это выглядит так:
Ложноположительных результатов получилось 501 из 10 тысяч, или ожидаемые 5%. Обратите внимание, что уровень значимости не достигает значения в 5% даже в конце, так как эти 5% должны «размазаться» по всем проверкам. В компании мы пользуемся именно этой поправкой, если запускаем тест с возможностью ранней остановки. Прочитать про эти же и другие поправки можно по ссылке.
Калькулятор A/B-тестов
Специфика нашего продукта такова, что распределение любой метрики очень сильно меняется в зависимости от аудитории теста (например, номера класса) и времени года. Поэтому не получится принять за дату окончания теста правила в духе «тест закончится, когда в каждой группе наберётся 1 млн пользователей» или «тест закончится, когда количество решённых заданий достигнет 100 млн». То есть получится, но на практике для этого надо будет учесть слишком много факторов:
Все метрики у нас рассчитываются на уровне объектов теста. Если метрика — количество решённых задач, то в тесте на уровне учителей это будет сумма решённых задач его учениками. Так как мы пользуемся критерием Стьюдента, можно заранее рассчитать нужные калькулятору агрегаты по всем возможным срезам. Для каждого дня со старта теста нужно знать количество людей в тесте  , среднее значение метрики
, среднее значение метрики  и её дисперсию
и её дисперсию  . Зафиксировав доли контрольной группы
. Зафиксировав доли контрольной группы  , экспериментальной группы
, экспериментальной группы  и ожидаемый прирост от теста
и ожидаемый прирост от теста  в процентах, можно рассчитать ожидаемые значения статистики Стьюдента
в процентах, можно рассчитать ожидаемые значения статистики Стьюдента  и соответствующее p-value на каждый день теста:
и соответствующее p-value на каждый день теста:

Далее легко получить значения p-value на каждый день:
Зная p-value и уровень значимости с учетом всех поправок на каждый день теста, для любой продолжительности теста можно рассчитать минимальный аплифт, который можно задетектировать (в англоязычной литературе — MDE, minimal detectable effect). После этого легко решить обратную задачу — определить количество дней, необходимое для выявления ожидаемого аплифта.
Заключение
В качестве заключения хочу напомнить основные посылы статьи: