What is Camel?
Apache Camel ™ is a versatile open-source integration framework based on known Enterprise Integration Patterns.
Camel empowers you to define routing and mediation rules in a variety of domain-specific languages (DSL, such as Java, XML, Groovy, Kotlin, and YAML). This means you get smart completion of routing rules in your IDE, whether in a Java or XML editor.
Apache Camel uses URIs to work directly with any kind of transport or messaging model such as HTTP, ActiveMQ, JMS, JBI, SCA, MINA or CXF, as well as pluggable Components and Data Format options. Apache Camel is a small library with minimal dependencies for easy embedding in any Java application. Apache Camel lets you work with the same API regardless which kind of transport is used — so learn the API once and you can interact with all the Components provided out-of-box.
Apache Camel provides support for Bean Binding and seamless integration with popular frameworks such as CDI, Spring. Camel also has extensive support for unit testing your routes.
The following projects can leverage Apache Camel as a routing and mediation engine:
Apache ServiceMix — a popular distributed open source ESB and JBI container
Apache ActiveMQ — a mature, widely used open source message broker
Apache CXF — a smart web services suite (JAX-WS and JAX-RS)
Apache Karaf — a small OSGi based runtime in which applications can be deployed
Apache MINA — a high-performance NIO-driven networking framework
So don’t get the hump — try Camel today! 🙂
Too many buzzwords — what exactly is Camel?
Okay, so the description above is technology focused. There’s a great discussion about Camel at Stack Overflow. We suggest you view the post, read the comments, and browse the suggested links for more details.
© 2004-2021 The Apache Software Foundation.
Apache Camel, Camel, Apache, the Apache feather logo, and the Apache Camel project logo are trademarks of The Apache Software Foundation. All other marks mentioned may be trademarks or registered trademarks of their respective owners.
Полезные приёмы работы с Apache Camel
Если вам приходилось создавать интеграционные решения на Java, наверняка, вам знаком замечательный Java framework под названием Apache Camel. Он с лёгкостью осуществит связку между несколькими сервисами, импортирует данные из файлов, баз данных и прочих источников, оповестит вас о различных событиях в Jabber-клиент или по E-mail, станет основой для композитного приложения на базе большого числа других приложений.
Введение
В основе модели Apache Camel лежит понятие маршрутов (routes), которые можно конфигурировать как статически (например, в файле Spring-контекста), так и во время работы приложения. По маршрутам ходят караваны сообщений, попутно попадая в различные обработчики, конверторы, аггрегаторы и прочие трансформеры, что в конечном итоге позволяет обработать данные из множества различных источников в едином приложении и передать эти данные другим сервисам или сохранить в какое-либо хранилище.
В общем и целом Camel — вполне самодостаточный фреймворк. Используя его, зачастую, даже не приходится писать собственный код — достаточно лишь набрать правильный маршрут, который позволит решить поставленную задачу. Однако, всё же для построения собственной модели обработки данных, может потребоваться написание кода.
Так было и у нас. Мы используем Camel для реализации конвейеров по обработке множества сообщений из различных источников. Подобный подход позволяет, например, следить за состоянием сервисов, своевременно оповещая о проблемах, получать аггрегированные аналитические срезы, готовить данные для отправки в другие системы и прочее. Поток обрабатываемых и «перевариваемых» сообщений в систему может быть довольно большим (тысячи сообщений в минуту), поэтому мы стараемся использовать горизонтально масштабируемые решения там, где это возможно. Например, у нас есть система отслеживания состояний выполняемых тестов и мониторингов сервисов. Подобных тестов выполняется по миллиону ежедневно, а сообщений для контроля процесса их выполнения мы получаем в разы больше.
Чтобы «усвоить» подобный объём сообщений, необходимо чётко определить стратегию аггрегации — от большего параллелизма к меньшему. Помимо этого необходимо иметь хотя бы базовую горизонтальную масштабируемость и отказоустойчивость сервиса.
В качестве очереди сообщений мы используем ActiveMQ, в качестве оперативного хранилища — Hazelcast.
Масштабирование
Для организации параллельной обработки организуется кластер из нескольких равноправных серверов. На каждом из них живёт брокер ActiveMQ, в очереди которого складываются сообщения, поступающие по HTTP-протоколу. HTTP-ручки находятся за балансировщиком, распределяющим сообщения по живым серверам.
Входную очередь сообщений на каждом сервере разбирает Camel-приложение, использующее кластер Hazelcast для хранения состояний, а также, при необходимости, синхронизации обработки. ActiveMQ также объеденены в кластер с использованием NetworkConnectors, и могут «делиться» сообщениями друг с другом.
В целом схема выглядит следующим образом: 
Как видно из схемы, выход из строя одного из компонентов системы не нарушает её работоспособность, с учётом равноправия элементов. К примеру, если выходит из строя обработчик сообщений на одном из серверов, ActiveMQ начинает отдавать сообщения из своих очередей другим. Если падает один из брокеров ActiveMQ, то обработчик «зацепляется» за соседний. Ну и наконец, если выходит из строя весь сервер, остальные сервера продолжают трудиться в поте лица, как ни в чём не бывало. Для повышения сохранности данных ноды Hazelcast хранят резервные копии данных своих соседей (копии осуществляются асинхронно, их число на каждой ноде настраивается дополнительно).
Данная схема также позволяет без особых затрат масштабировать сервис, добавляя дополнительные сервера, и тем самым увеличивая вычислительный ресурс.
Распределённые аггрегаторы
Чтобы воспользоваться подобным репозиторием, теперь нужно лишь подключить к проекту Hazelcast и объявить его в контексте, а затем добавить и набор репозиториев с указанием на инстанс Hazelcast. Важно помнить, что каждый аггрегатор должен иметь собственное пространство ключей, а поэтому ему необходимо передавать также имя репозитория. В настройках Hazelcast нужно прописать все сервера, которые входят в кластер.
Таким образом, мы получаем возможность использовать аггрегаторы в распределённой среде, не задумываясь о том на каком именно сервере произойдёт аггрегация.
Распределённые таймеры
Число состояний, хранящихся в кластере достаточно велико. Но не все из них нужны постоянно. К тому же, некоторые состояния (например, состояние тестов, которые давно не используются, а следовательно для них давно не было сообщений) вообще хранить не нужно. От подобных состояний хочется избавляться и дополнительно оповещать об этом прочие системы. Для этого необходимо с заданной периодичностью проверять состояния аггрегаторов на предмет устаревания и удалять их.
Простой способ это сделать — добавить периодическую задачу, например, с помощью Quartz. К тому же, Camel это сделать позволяет. Однако, необходимо помнить, что выполнение происходит в кластере со множеством равноправных серверов. И не очень хочется, чтобы периодические задачи Quartz срабатывали на всех одновременно. Во избежание этого, достаточно сделать синхронизацию опять же с помощью локов Hazelcast. Но как заставить Quartz инициализироваться только на одном сервере, вернее в какой момент производить синхронизацию?
Для инициализации Camel-контекста и всех остальных компонентов системы мы используем Spring, и чтобы заставить Quartz стартовать планировщик только на одном сервере из кластера, во-первых, необходимо отключить его автоматический запуск, явно объявив в контексте:
Во-вторых, нужно где-то произвести синхронизацию и запустить планировщик только если удалось захватить лок, а затем ожидать следующего момента его захвата (в случае, если предыдущий сервер, захвативший лок, вышел из строя или по какой-то причине его отпустил). Это в Spring можно реализовать несколькими вариантами, например, через ApplicationListener, который позволяет обработать события запуска контекста:
Получим следующую реализацию класса инициализации планировщика:
Таким образом, мы получим возможность использовать периодические задачи рекомендуемым в Camel способом и с учётом распределённой среды выполнения. Например, так:
Finite state machine
Подбирая варианты реализации подобной стратегии аггрегации, мы пришли к выводу, что необходима некая адаптированная к реалиям обработки сообщений модель конечных автоматов. Во-первых, сообщения поступающие на вход аггрегаторов — это некий набор объектов. Каждое событие имеет собственный тип, а следовательно легко ложится на классы в Java. Для описания типов событий мы используем xsd-схему, по которой с помощью xjc генерируем набор классов. Эти классы легко сериализуются и десериализуются в xml и json, с использованием jaxb. Состояния, хранящиеся в Hazelcast также представляются набором классов, сгенерированных по xsd. Таким образом, нам необходимо было найти реализацию конечных автоматов, позволяющую легко оперировать переходами между состояниями на основе типа сообщения и типа текущего состояния. И ещё хотелось, чтобы задавались эти переходы декларативно, а не императивно, как во множестве подобных библиотек. Легковесной реализации подобной функциональности мы не нашли, а поэтому решили написать свою собственную, учитывающую наши потребности и хорошо ложащуюся в основу обработки сообщений, приходящих по маршруту в Camel.
Небольшая библиотечка, реализующая наши потребности получила название Yatomata (от слов Yet Another auTomata) и доступна на github.
Было решено несколько упростить модель FSM — например, контекст задаётся объектом текущего состояния, сообщение также хранит некоторые данные. Однако, переходы при этом определяются только типами состояний и сообщений. Стейт-машина определяется для класса, который используется в качестве аггрегатора. Для этого класс помечается аннотацией @FSM. Для неё определено исходное состояние (start) и набор переходов, некоторые из которых останавливают аггрегацию (stop=true), автоматически отправляя накопленное состояние далее по маршруту.
Набор переходов декларируется аннотацией @Transitions и массивом аннотаций @Transit, в каждом из которых можно задать набор исходных состояний (from), конечное состояние (to), набор событий, по которым данный переход активируется (on), а также указать является ли это состояние окончанием работы машины (stop). Для обработки переходов предусмотрены аннотации @OnTransit, @BeforeTransit, а также @AfterTransit, которыми можно пометить публичные методы внутри класса. Эти методы будут вызваны в том случае, если найден соответствующий переход, удовлетворяющий его сигнатуре.
Работа со стейт-машиной осуществляется следующим образом:
Путём реализации интерфейса AggregationStrategy, мы создали FSMAggregationStrategy, объявление которого в контексте Spring происходит так:
Простейшая реализация стратегии аггрегации в случае использования этой стейт-машины может выглядеть следующим образом:
Apache Camel — разработка приложения с нуля (часть 1/2)
Прежде чем мы начнем
Некоторое время назад я написал учебник по Spring Integration, чтобы продемонстрировать, как использовать Spring Integration в примере приложения, основанном на реальной системе обработки счетов. Я получил довольно положительные отзывы об этом, поэтому я решил, что покажу вам, как мы можем создать то же самое приложение, используя Apache Camel — величайшего конкурента Spring Integration.
Приложение, которое мы собираемся создать, будет почти таким же, как и текст этого урока. Новые части будут в основном посвящены Apache Camel и его использованию.
Вы можете либо следовать пошаговому руководству шаг за шагом и самостоятельно создавать приложение, либо вы можете продолжить и получить код с github: СКАЧАТЬ ИСТОЧНИКИ ЗДЕСЬ: https://github.com/vrto/apache-camel-invoices
Приложение для обработки счетов — функциональное описание
Представьте, что вы работаете в какой-то компании, которая периодически получает большое количество счетов от различных подрядчиков. Мы собираемся создать систему, которая сможет получать счета, отфильтровывать соответствующие, создавать платежи (местные или иностранные) и отправлять их в некоторые банковские службы. Несмотря на то, что система будет довольно наивной и, конечно, не готовой для предприятия, мы постараемся создать ее с хорошей масштабируемостью, гибкостью и независимым дизайном.
Apache Camel — это интегрированная среда — это означает, что она предоставляет содержательные абстракции для сложных систем, которые вы интегрируете.
Для этого урока есть много важных понятий. Позвольте мне подвести их итог для вас:
Теперь, когда у нас есть некоторое понимание основных понятий, давайте взглянем на следующую картину, которая представляет собой краткое изложение системы, и пройдемся по важным частям:
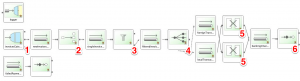
На рисунке вы видите маршрут, который иллюстрирует нашу структуру обмена сообщениями и основные компоненты системы — они отмечены красными цифрами. Давайте пройдемся по ним (мы вернемся к каждому компоненту более подробно позже):
Apache Camel
Camel is an Open Source integration framework that empowers you to quickly and easily integrate various systems consuming or producing data.

What’s New?
Camel Quarkus 2.5.0 Released
Camel Quarkus 2.5.0 Released. Read More
New release of VS Code AtlasMap 0.1.0
New release of VS Code AtlasMap 0.1.0: new development flow. Read More
Karavan Serverless mode
Karavan Serverless mode with Camel-K on Kubernetes. Read More
Why Camel?
Based on Enterprise Integration Patterns
Camel supports most of the Enterprise Integration Patterns from the excellent book by Gregor Hohpe and Bobby Woolf, and newer integration patterns from microservice architectures to help you solve your integration problem by applying best practices out of the box.


Runs Everywhere
Apache Camel is standalone, and can be embedded as a library within Spring Boot, Quarkus, Application Servers, and in the clouds. Camel subprojects focus on making your work easy.
Packed with Components
Packed with several hundred components that are used to access databases, message queues, APIs or basically anything under the sun. Helping you integrate with everything.


Supports over 50 Data Formats
Camel supports around 50 data formats, allowing to translate messages in multiple formats, and with support from industry standard formats from finance, telco, health-care, and more.
Apache Camel Projects
Camel Core
Apache Camel helps you integrate various systems consuming or producing data.

Camel K
Apache Camel K is a lightweight integration framework that runs natively on Kubernetes.

Camel Quarkus
Apache Camel Quarkus packages 280+ Camel components as Quarkus extensions.

Camel Kafka Connector
Apache Camel Kafka Connector embeds Camel within Kafka Connect.

Camel Spring Boot
Apache Camel Spring Boot runs Camel on Spring Boot and provides starters for Camel components.

Camel Karaf
Apache Camel Karaf makes running Apache Camel components to run in the OSGi environment.
Apache & OpenSource

Camel is your project!
Camel is an Apache Software Foundation project, available under the Apache v2 license. It’s a complete open community, always listening to proposals and comments.
Sources, mailing lists, issue tracker: it’s fully open, you can access directly.
We also love contributions: don’t hesitate to contribute. You can contribute by editing this page!
© 2004-2021 The Apache Software Foundation.
Apache Camel, Camel, Apache, the Apache feather logo, and the Apache Camel project logo are trademarks of The Apache Software Foundation. All other marks mentioned may be trademarks or registered trademarks of their respective owners.
Apache Camel — Краткое руководство
Рассмотрим ситуацию, когда крупный онлайн-магазин в вашем городе, такой как Bigbasket в Индии, предлагает вам разработать для них ИТ-решение. Стабильное и масштабируемое решение поможет им преодолеть проблемы обслуживания программного обеспечения, с которыми они сталкиваются сегодня. Этот интернет-магазин работает уже в течение последнего десятилетия. Магазин принимает онлайн-заказы на различные категории продуктов от своих покупателей и распределяет их соответствующим поставщикам. Например, предположим, вы заказываете немного мыла, масла и молока; Эти три предмета будут распространены среди трех соответствующих поставщиков. Затем три поставщика отправят свои поставки в общий пункт распределения, откуда весь центр доставки будет выполнять весь заказ. Теперь давайте посмотрим на проблему, с которой они сталкиваются сегодня.
Когда этот магазин начал свою деятельность, он принимал заказы в виде простого текстового файла, разделенного запятыми. Через некоторое время магазин переключился на размещение заказов на основе сообщений. Позже, некоторые разработчики программного обеспечения предложили размещение заказа на основе XML. В конце концов, магазин даже адаптировал интерфейс веб-службы. Теперь возникает настоящая проблема. Заказы теперь приходят в разных форматах. Очевидно, что каждый раз, когда компания обновляла формат приема заказов, она не хотела ломать ранее развернутый интерфейс, чтобы не вызывать недоразумения в уме клиента.
В то же время, поскольку бизнес продолжал расти, магазин периодически добавлял новых поставщиков в свой репертуар. У каждого такого поставщика был свой протокол приема заказов. Еще раз, мы сталкиваемся с проблемой интеграции; Архитектура нашего приложения должна быть масштабируемой, чтобы приспособить новых поставщиков к их уникальному механизму размещения заказов.
Вся ситуация показана на следующем рисунке —
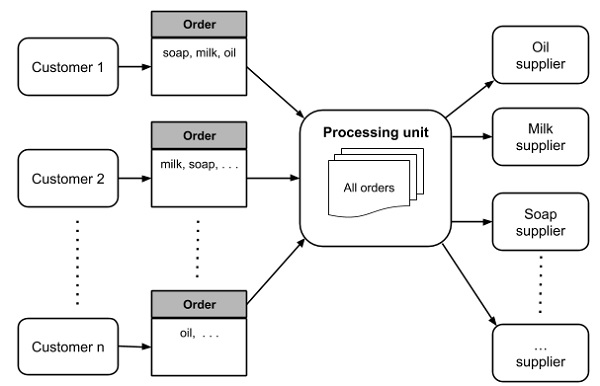
Теперь давайте посмотрим, как Apache Camel может прийти на помощь, чтобы предоставить элегантную, поддерживаемую, масштабируемую архитектуру решения для описанного сценария.
Прежде чем приступить к решению, нам нужно сделать небольшое предположение. Для всех обсуждений в этом руководстве мы будем предполагать, что онлайн-заказы размещаются в формате XML. Типичный формат файла заказа, который мы будем использовать в наших обсуждениях, показан здесь —
Мы будем использовать вышеупомянутый шаблон XML, чтобы проиллюстрировать примеры Camel в этом руководстве.
Apache Camel — Обзор
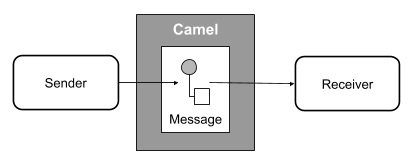
Верблюд — это черный ящик, который получает сообщения от одной конечной точки и отправляет ее другой. Внутри черного ящика сообщения могут быть обработаны или просто перенаправлены.
Итак, почему есть рамки для этого? В практических ситуациях, как показано во вводном примере, может быть много отправителей и много получателей, каждый из которых следует своему собственному протоколу, такому как ftp, http и jms. Системе может потребоваться множество сложных правил, например, сообщение от отправителя A должно быть доставлено только в B & C. В ситуациях вам может потребоваться перевести сообщение в другой формат, который ожидает получатель. Этот перевод может быть предметом определенных условий, основанных на содержании сообщения. По сути, вам может потребоваться выполнять трансляцию между протоколами, склеивать компоненты, определять правила маршрутизации и обеспечивать фильтрацию на основе содержимого сообщения. Это показано на следующем рисунке —
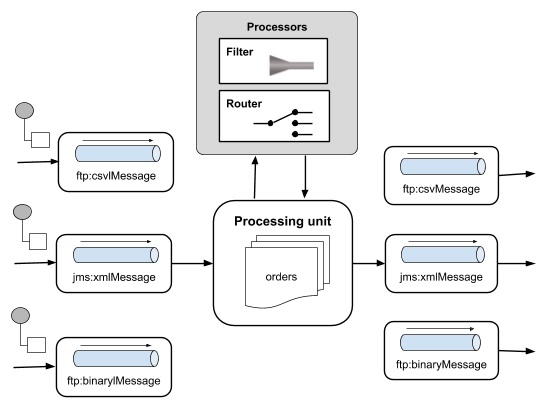
Чтобы удовлетворить вышеупомянутые требования и спроектировать правильную архитектуру программного обеспечения для многих таких ситуаций, Грегор Хоуп и Бобби Вульф в 2003 году задокументировали шаблоны интеграции предприятия ( EIP ). Apache Camel обеспечивает реализацию этих шаблонов, и цель этого учебного пособия — научить Вы знаете, как использовать Camel в ситуациях, подобных описанной во введении.
Apache Camel — это фреймворк с открытым исходным кодом. Это промежуточное программное обеспечение, ориентированное на сообщения, которое предоставляет механизм маршрутизации и передачи на основе правил. Вы можете определить правила, например, если это «молочный» заказ, перенаправить его поставщику молока, а если это «нефтяной» заказ, перенаправить его поставщику масла и т. Д. Используя Camel, вы сможете реализовать эти правила и выполнить маршрутизацию в привычном Java-коде. Это означает, что вы можете использовать знакомую вам Java IDE для определения этих правил в безопасной среде. Нам не нужно использовать файлы конфигурации XML, которые обычно бывают громоздкими. Однако Camel поддерживает настройку XML через Spring Framework, если вы предпочитаете использовать XML для настройки правил. Вы можете даже использовать конфигурационные файлы Blueprint XML и даже Scala DSL, если вы любитель Scala. Это также означает, что вы можете использовать вашу любимую Java, Scala IDE или даже простой редактор XML для настройки правил.
Входными данными для этого механизма могут быть текстовый файл с разделителями-запятыми, POJO (простой старый Java-объект), XML — любой из нескольких других форматов, поддерживаемых Camel. Точно так же выходные данные механизма могут быть перенаправлены в файл, в очередь сообщений или даже на экран вашего монитора, чтобы вы могли просматривать заказы, отправленные соответствующим поставщикам. Они называются конечными точками, и Camel поддерживает шаблон EIP сообщения конечной точки. Конечные точки Camel обсуждаются позже в главе «Конечные точки».
Apache Camel — Особенности
Посмотрев обзор Apache Camel, давайте теперь углубимся в его возможности, чтобы увидеть, что он предлагает. Мы уже знаем, что Apache Camel — это инфраструктура Java с открытым исходным кодом, которая, по сути, обеспечивает реализацию различных EIP. Camel упрощает интеграцию, предоставляя возможность подключения к очень большому количеству транспортов и API. Например, вы можете легко направить JMS в JSON, JSON в JMS, HTTP в JMS, FTP в JMS, даже HTTP в HTTP и подключение к микросервисам. Вам просто нужно предоставить соответствующие конечные точки на обоих концах. Верблюд является расширяемым и, таким образом, в будущем можно будет легко добавить дополнительные конечные точки в платформу.
Чтобы соединить EIP и транспорты вместе, вы используете доменные языки (DSL), такие как Java, Scala и Groovy. Типичное правило маршрутизации Java может выглядеть так:
Вот некоторые из наиболее важных функций Camel, которые вы найдете полезными при разработке приложений Camel:
Camel поддерживает подключаемые форматы данных и преобразователи типов для таких преобразований сообщений, поэтому в будущем могут быть добавлены новые форматы и преобразователи. В настоящее время он поддерживает несколько популярных форматов и конвертеров; назвать несколько — CSV, EDI, JAXB, JSON, XmlBeans, XStream, Flatpack, Zip.
Camel поддерживает подключаемые языки для написания предикатов в DSL. Некоторые из поддерживаемых языков включают JavaScript, Groovy, Python, PHP, Ruby, SQL, XPath, XQuery.
Camel поддерживает модель POJO, так что вы можете подключать Javabeans в разных точках.
Camel облегчает тестирование таких больших распределенных и асинхронных систем с помощью обмена сообщениями.
Camel поддерживает подключаемые форматы данных и преобразователи типов для таких преобразований сообщений, поэтому в будущем могут быть добавлены новые форматы и преобразователи. В настоящее время он поддерживает несколько популярных форматов и конвертеров; назвать несколько — CSV, EDI, JAXB, JSON, XmlBeans, XStream, Flatpack, Zip.
Camel поддерживает подключаемые языки для написания предикатов в DSL. Некоторые из поддерживаемых языков включают JavaScript, Groovy, Python, PHP, Ruby, SQL, XPath, XQuery.
Camel поддерживает модель POJO, так что вы можете подключать Javabeans в разных точках.
Camel облегчает тестирование таких больших распределенных и асинхронных систем с помощью обмена сообщениями.
Давайте теперь разберемся с архитектурой Camel и посмотрим, как реализованы различные функции.
Apache Camel — Архитектура
Архитектура Camel состоит из трех компонентов — модуля интеграции и маршрутизатора, процессоров и компонентов. Это показано на следующем рисунке —
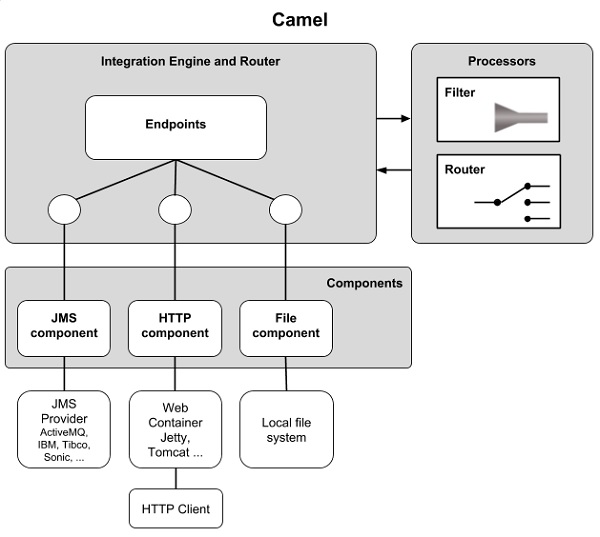
Само ядро Camel очень маленькое и содержит 13 основных компонентов. Остальные 80+ компонентов находятся за пределами ядра. Это помогает поддерживать низкую зависимость от места его развертывания и способствует расширению в будущем. Модуль Компоненты обеспечивает интерфейс конечной точки с внешним миром. Конечные точки задаются URI, такими как file: / order и jms: orderQueue, которые вы видели в предыдущей главе.
Модуль Processors используется для манипулирования и передачи сообщений между конечными точками. EIP, которые я упоминал ранее, реализованы в этом модуле. В настоящее время он поддерживает более 40 шаблонов, как описано в книге EIP и других полезных процессорах.
Процессоры и конечные точки соединены вместе в Integration Engine и модуле маршрутизатора с использованием DSL. При их подключении вы можете использовать фильтры для фильтрации сообщений на основе определенных пользователем критериев. Как упоминалось ранее, у вас есть несколько вариантов написания этих правил. Для этого вы можете использовать Java, Scala, Groovy или даже XML.
Apache Camel — CamelContext
CamelContext обеспечивает доступ ко всем другим сервисам в Camel, как показано на следующем рисунке —
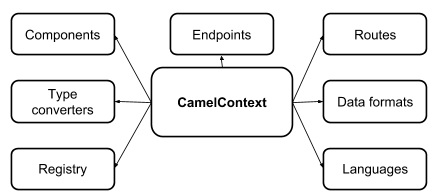
Фрагмент кода здесь даст вам представление о том, как CamelContext создается в приложении Camel —
Что происходит внутри экземпляра RouteBuilder, описано далее.
Маршруты
Вот типичный пример того, как создается маршрут —
Выбор языка
Вы можете создавать маршруты на разных языках. Вот несколько примеров того, как один и тот же маршрут определяется на трех разных языках:
Java DSL
Spring DSL
Scala DSL
фильтры
В этом примере мы использовали предикат xpath для фильтрации. Если вы предпочитаете использовать Java-класс для фильтрации, используйте следующий код —