Apache jMeter – нагрузочное тестирование веб-сервера
Для его работы требуется Java и x-server на машине, с которой будет проводиться тестирование.
$ tar xpf apache-jmeter-2.9.tgz
$ cd apache-jmeter-2.9
Содержимое выглядит так:
Для запуска выполняем:
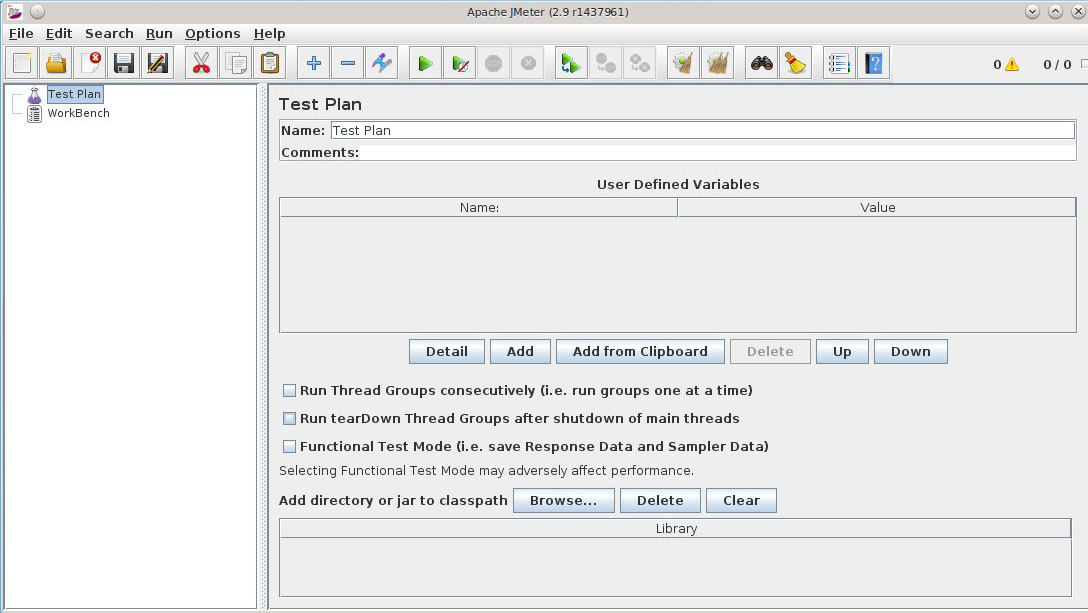
Переименуем наш тест в KZ test 1.
Кликаем правой кнопкой на KZ test 1 и добавляем новую группу тестов и способов просмотра/анализа – Add > Treads(Users) > Thread group :
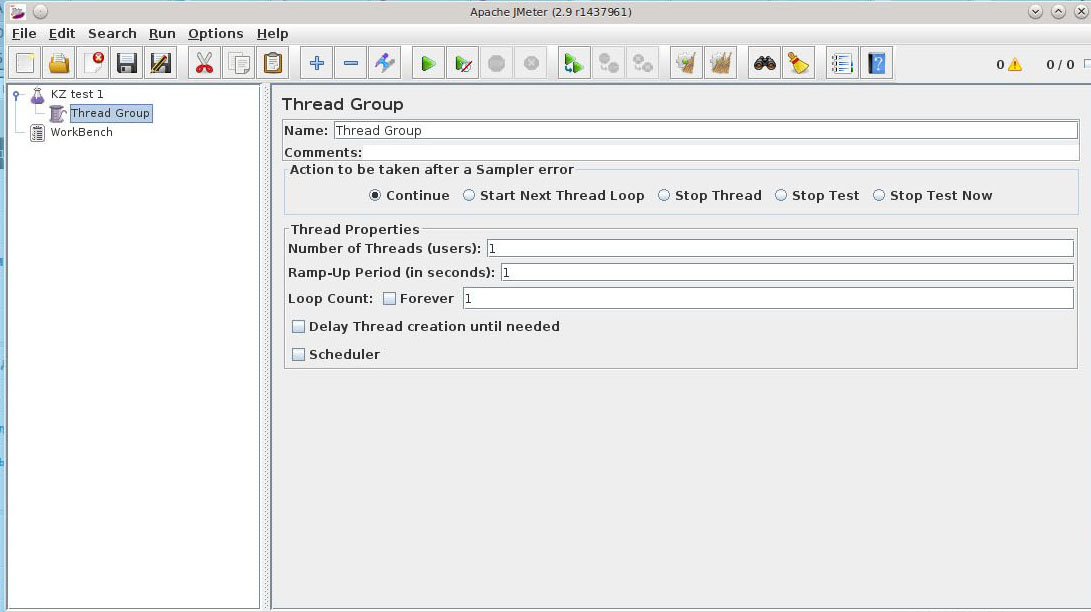

Теперь добавляем в тест средства отображения:
Выбираем View Results in Table и в поле Write results to… укажем путь к нашему log-file /home/setevoy/jmeter.log – полезно при сбоях и для последующего анализа проблем:

Для интереса откроем просмотр лога Apache на тестируемом сервере:
Видим в логе поток записей типа:
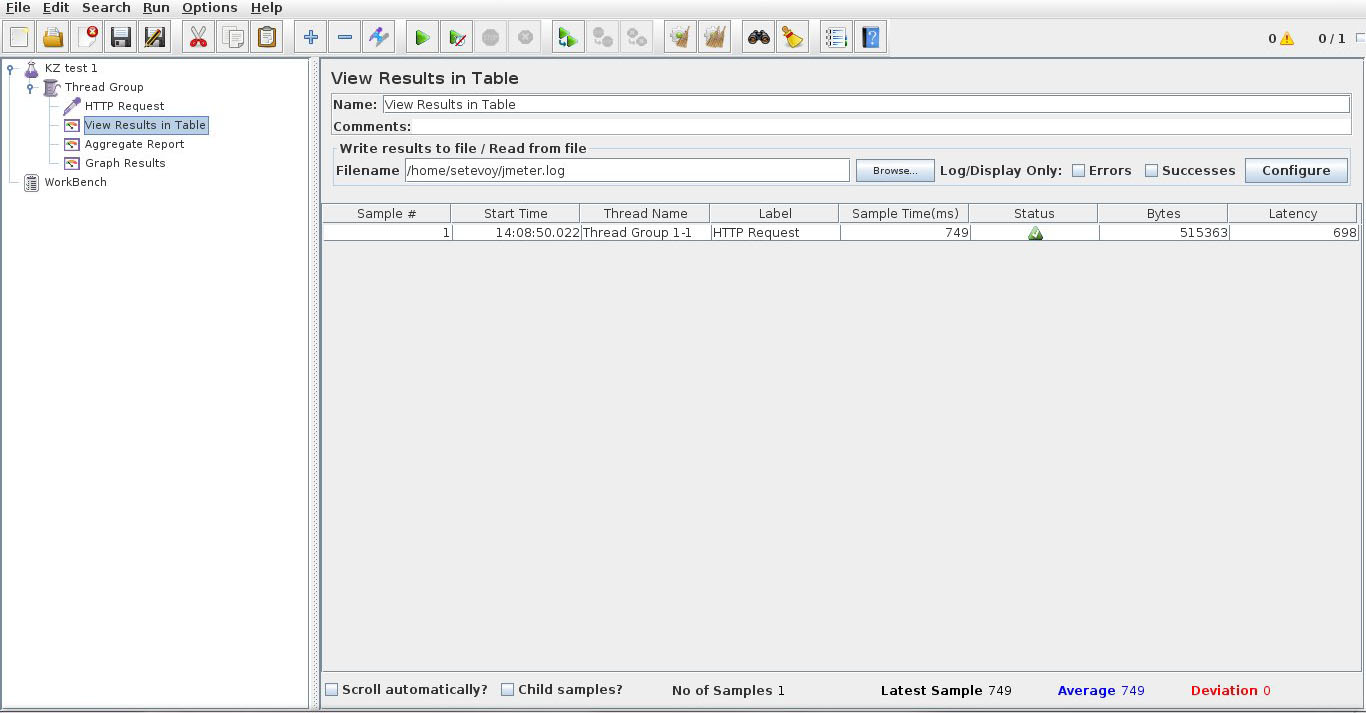
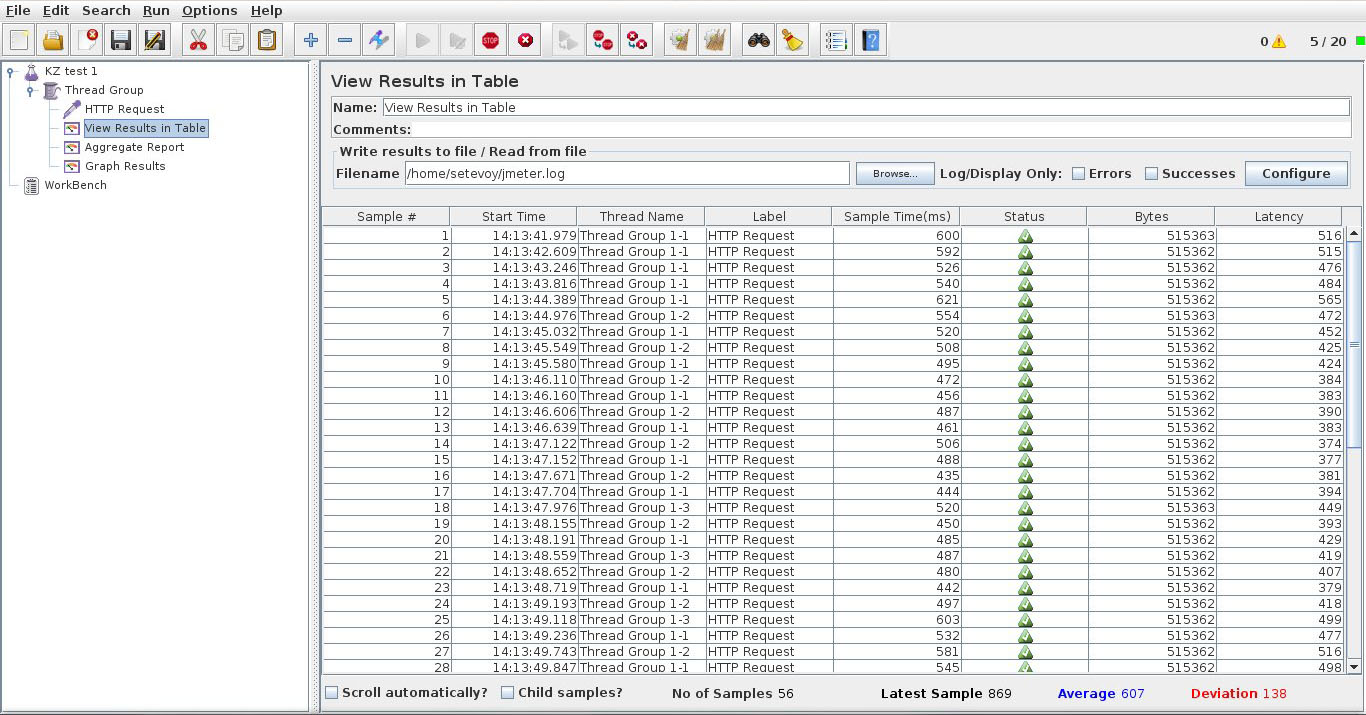
Смотрим Status колонку – должно быть OK.
С такими настройками будет эмулировано подключение 20-ти пользователей в течении 60-ти секунд:

Сохраняем настройки – Ctrl+S и Сtrl+E что бы очистить старые данные. Для запуска нажимаем Ctrl+R:
Посмотрим на вывод top сервера:
top – 14:13:54 up 3 days, 5 min, 3 users, load average: 14.81, 4.03, 1.36
Tasks: 136 total, 21 running, 115 sleeping, 0 stopped, 0 zombie
Cpu(s): 96.8%us, 2.1%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.2%hi, 0.9%si, 0.0%st
Mem: 4063160k total, 1212044k used, 2851116k free, 134872k buffers
Swap: 1740792k total, 0k used, 1740792k free, 389924k cached
На Graph results можно посмотреть графики “отзывчивости” сервера:
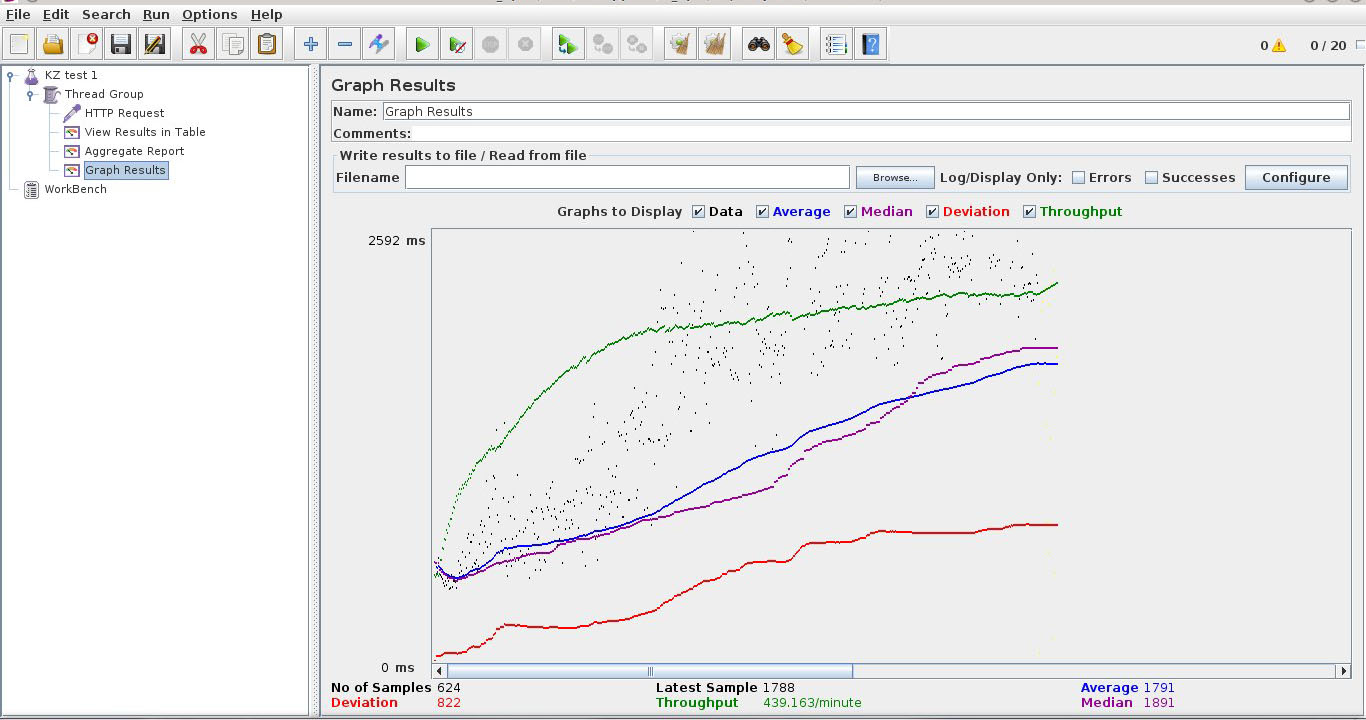
Значения предоставлены в миллисекундах:
Data — время отклика на каждый выполненный запрос.
Average — среднее время отклика сервера, объективный график нагрузки.
Median — значение медианы (используется в статистике, этими данными можно не пользоваться).
Deviation — погрешность, стандартное отклонение.
Throughput — скорость выполнения самого запроса.
На странице View results Tree наблюдаем такую картину:

Если завис сам jMeter (случается) – убиваем процесс, перезапускаем, правой кнопкой на Test Plan – Open :
Кстати, пока jMeter “висит” – процесс тестирования обычно продолжается, что чревато неприятными последствиями, если тестируете рабочий сервер.
Теперь выполним тестирование с помощью access.log файла с сервера, который мы предварительно скачали к себе на компьютер.
Добавляем Thread Group->Add->Sampler->Access Log Sampler.
Указываем сервер и путь к лог-файлу:
Что бы подробнее почитать что за ошибки – переходим на View Results Tree и выделяем нужную строку с ошибкой:
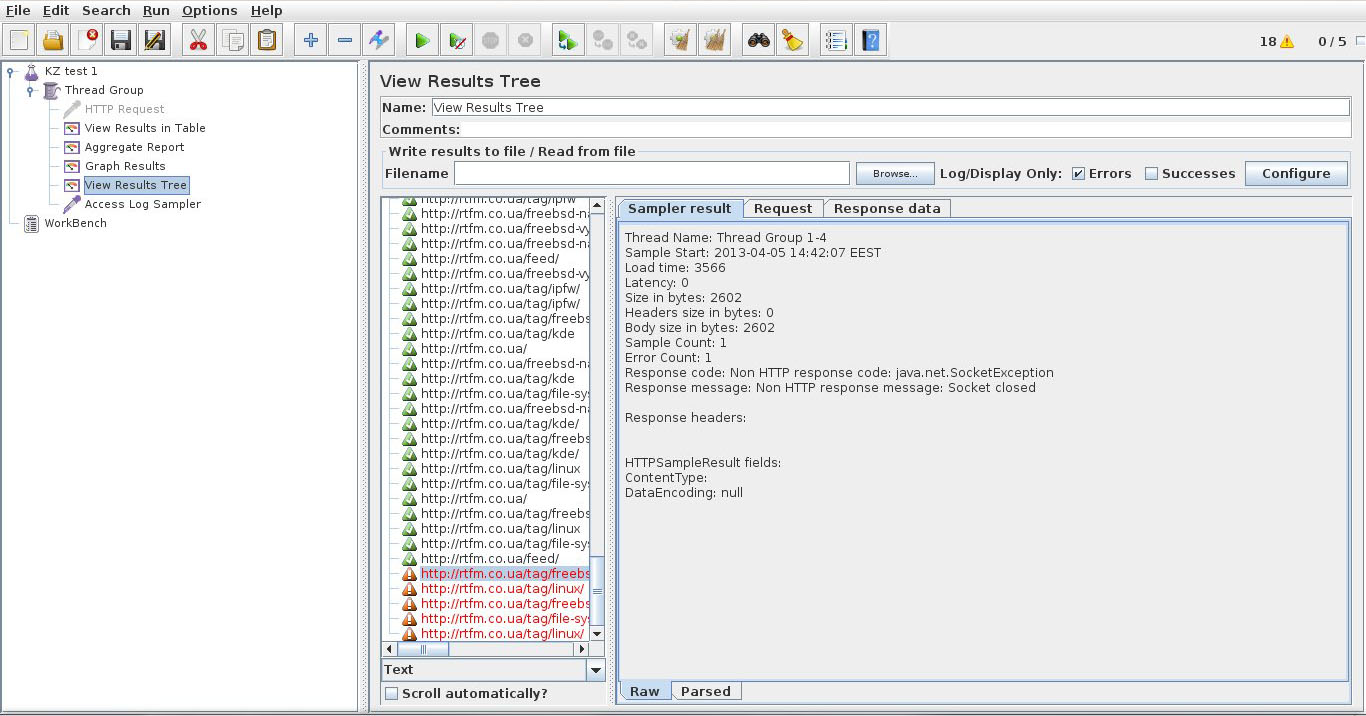
Среднее время отклика ( Average ) растет, а скорость обработки ( Throughput ) не меняется. Это значит, что где-то на сервере операции становятся в очередь и производительности не хватает, чтобы обслужить все запросы.
Вернёмся к HTTP Request – выполняем Access Log Sampler > Disable, HTTP Request > Enable.
Ещё один вариант работы Apache jMeter – повторять запросы, выполненные именно вами. Мы будем выполнять любые действия через браузер, и при этом все необходимые элементы HTTP Request будут создаваться без нашего участия.

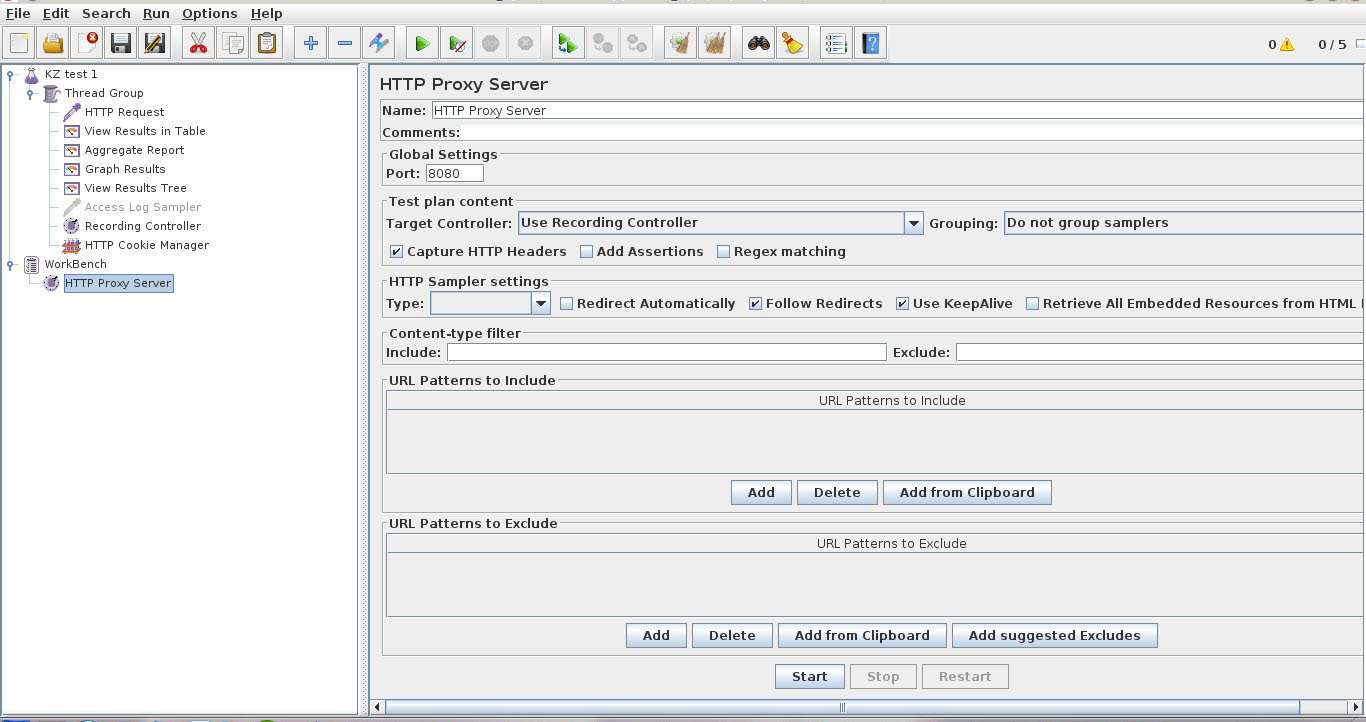
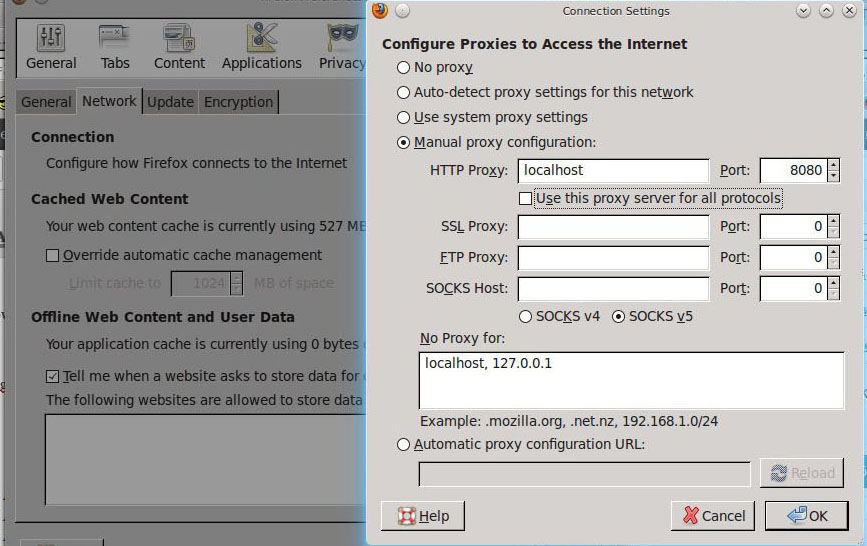
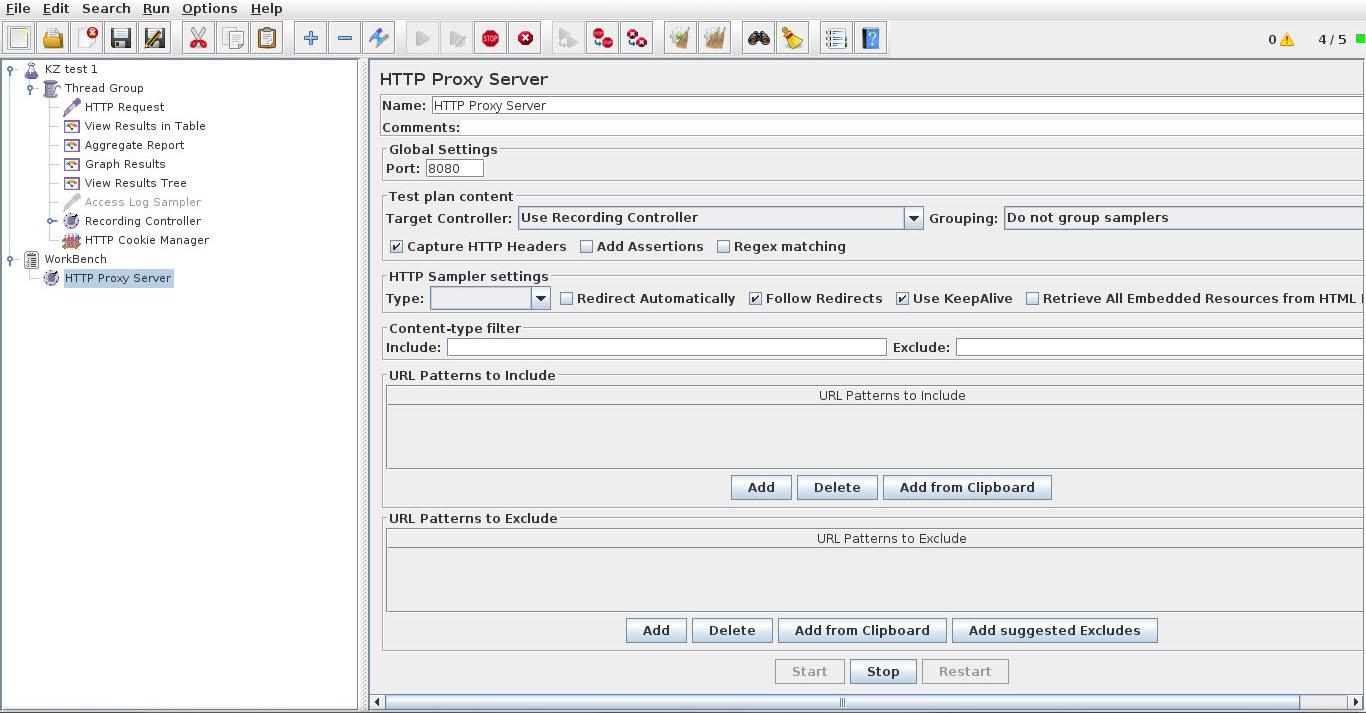
По сути здесь достаточно только изменить номер порта прокси-сервера, если порт по умолчанию 8080 у вас уже занят, например, можно поставить 8089. Если оставить в графе Target Controller значение Use Recording Controller, то все запросы, проходящие через прокси, будут записываться в первый попавшийся Recording Controller в нашем тест-плане. Но так как на данный момент он там всего один, то нас этот вариант устроит.
Идём тестировать – логинимся на какой-либо странице сервера, который тестируем:

В Thread Group у нас уже всё настроено.
Ctrl+S что бы сохранить все действия и настройки.
Можно найти страницу login.php и посмотреть сформированный запрос:

В целом – тестирование можно считать завершённым. Вообще, возможностей у Apache jMeter действительно много. Все они описаны на оф. странице.
Простой нагрузочный тест с Apache JMeter
По моим наблюдениям, разработчики довольно редко делают нагрузочное тестирование сайтов и веб-приложений. И бывает так, что выставят проект в Интернет, а тут вдруг посетители начнут ходить (хабраэффект, к примеру, случился), и сайт в самый подходящий момент ложится или начинает не по-детски тормозить.
Почему бы не избежать этих неприятностей, прогнав нагрузочный тест?
Наверное, кого-то останавливает неверное представление о том, что нагрузочное тестирование — это очень сложное дело, требующее специальных знаний. Однако не боги горшки обжигают. Если выбор — тестировать не слишком профессионально, или не тестировать вовсе, я бы выбрал первое. Тем более, что организовать примитивный тест производительности очень даже просто. Можно воспользоваться онлайн-средствами (см., например, Нагрузочное тестирование по-быстренькому), а можно замутить все своими руками, это ненамного сложнее.
Под катом рассказываю, как с нуля организовать незамысловатый нагрузочный тест сайта при помощи Apache JMeter.
Сразу хочу предупредить, что описанный подход (Log Replay) хорошо работает именно для сайтов, и не годится для веб-приложений, активно использующих POST, а также, по своей простоте, игнорирует существование cookie-based сессий. Кроме того, нежелательно тестировать проект, развернутый по адресу 127.0.0.1, результаты довольно сильно искажаюся из-за того, что JMeter и сайт тормозят друг друга (с другой стороны, плохо, когда сервер далеко — мешают задержки).
Итак, скачали JMeter (http://jakarta.apache.org/site/downloads/downloads_jmeter.cgi, разворачиваем архив, идем в директорию bin и запускаем jmeter.bat (делаю пример под Виндой). После небольшой паузы стартует GUI традиционного жабьего вида.
Слева наблюдаем дерево из 2 узлов: TestPlan и Workbench (про второй сразу забываем, он нам не понадобится). На Test Plan кликаем правым кликом и говорим Add->Thread Group (в интерфейсе можно увидеть много фишек разной степени полезности, но мы сейчас не отвлекаемся, а кратчайшим путем идем к нашему тесту, потом, если захотим — будем изучать обширные возможности JMeter подробнее).

Группа потоков добавилась:
Менять мы тут пока ничего не будем. Цифры все стоят по 1, что хорошо. Это один виртуальный пользователь, поторый один раз выполнит сценарий (в случае используемого нами Access Log Sampler’а — выполнит один запрос, соответствующий первой строчке лога). А нам для отладки теста больше и не надо.
Переименовывать Test Plan и Thread Group тоже не будем, эти названия у нас в рамках теста уникальны.
Правым кликом на Thread Group добавляем Access Log Sampler (Thread Group->Add->Sampler->Access Log Sampler)
Вбиваем адрес сервера и локальный путь к аксесс-логу (мы его утащили с сервера и положили к себе на диск):
Тест-план готов, переходим к его тестированию 🙂 и отладке (ничего-ничего, он может и с первого раза заработать).
File->Save, и так каждый раз после внесения изменений в тест-план. Это важно, JMeter другой раз виснет, и тест приходится восстанавливать по памяти.
Run->Clear All (на первый раз можно не делать, но потом все равно понадобится).
Run->Start.
И идем смотреть во View Results in Table. Если нам повезло, там будет одна строчка, с зеленой галочкой в колонке Status.
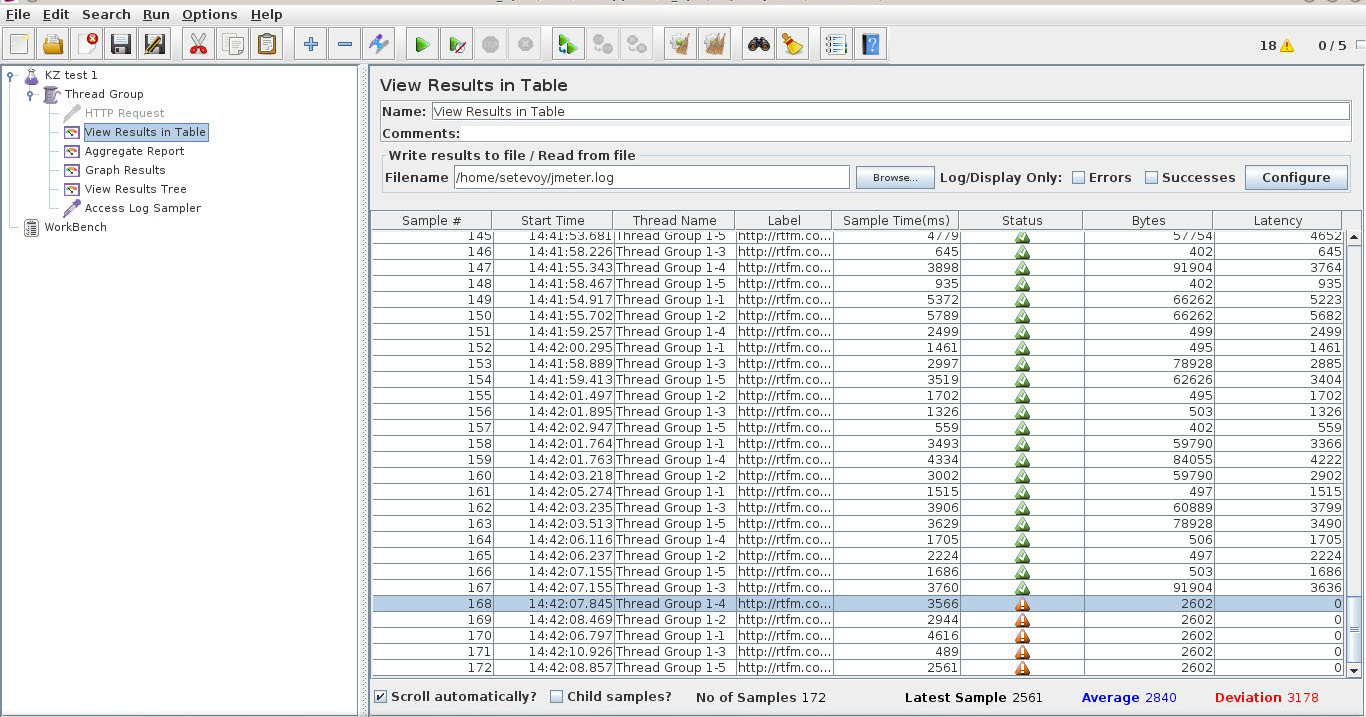
Если что-то пошло не так, в статусе будет ошибка:
Запускаем (File->Save, Run->Clear All, Run->Start). Идем смотреть во View Results in Table. Должно получиться как-то так:
В последней строчке ошибка, это JMeter испытывает расстройство оттого, что файл закончился (видно, привык работать с бесконечными файлами). К сожалению, по окончании файла сценарий останавливается, игнорируя настройку Action to be taken after a Sampler error = Continue (мне это кажется багом, а разработчикам наверняка фичей). Чтобы это не исказило результаты теста, лучше брать достаточно длинные аксесс-логи. Длинный файл несложно организовать из короткого с помощью copy в командной строке или Ctrl+C, Ctrl+V в текстовом редакторе. Для наших опытов больше 1000 строк в логе вряд ли понадобится.
Еще, прежде чем начать тест, добавим в начало сценария случайную задержку (Uniform Random Timer) 0-1000 миллисекунд, она обычно помогает несколько сгладить графики. Сценарий в результате работает так: ждет случайное количество миллисекунд, читает строку из лога, делает HTTP запрос, передает результаты листенерам, снова ждет, читает следующую строчку, и так далее.
Делаем первый, пристрелочный, тест. В свойствах группы потоков поставим: Number of Threads (users): 100, Ramp-Up Period (in seconds): 100. Мы собираемся натравить на сайт 100 виртуальных юзеров, вводя их в бой по одному в течении 100 секунд, то есть по юзеру в секунду. Цифры 100 и 100 я взял откуда-то с потолка, но надо же с чего-то начать.
Еще раз напомним себе, что мы имеем хорошие шансы притормозить или даже завалить сайт (что может быть нехорошо, если речь идет об уже работающем проекте). ОК, будучи в здравом уме и трезвой памяти, осознавая ответственность за свои действия, начинаем.
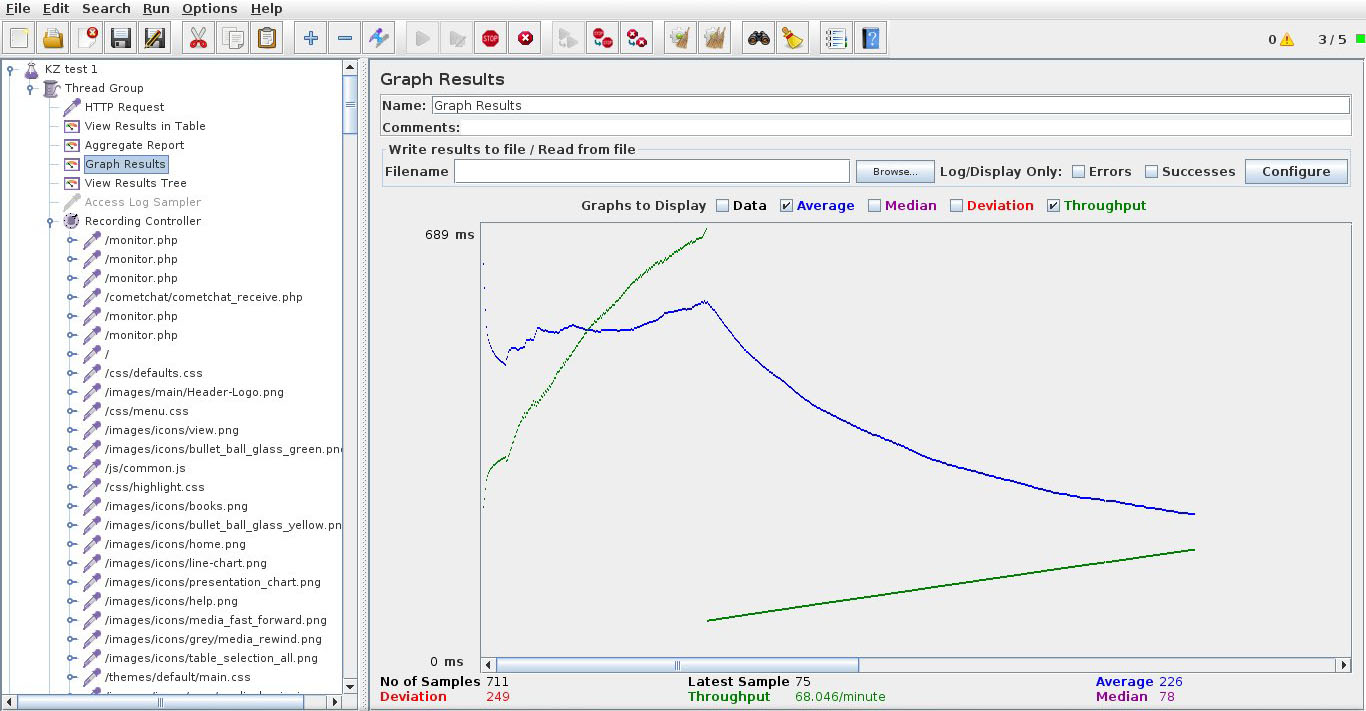
File->Save, Run->Clear All, Run->Start и идем смотреть Graph Results. Видим, скажем, такую картинку:
В правом верхнем углу можно наблюдать текущее количество виртуальных пользователей.
О чем говорит нам этот график? Среднее время отклика (Average) растет, а скорость обработки (Throughput) не меняется. Это значит, что где-то на сервере операции становятся в очередь, и производительности не хватает, чтобы обслужить все запросы. Зайдя браузером на сайт, убедимся, что он еле ворочается или вообще не респондит. Зачем зря мучить несчастного? Run->Stop. Ну вот, сайт снова ожил. Неудачная идея во время такого теста — отвлечься ненадолго и, вернувшись через несколько часов (как это бывает), обнаружить, что сайт полдня лежал.
В качестве содержательного результата мы получили одно число — максимальное значение Throughput (183 запроса в минуту). Можно считать его пределом производительности. Для начала этого числа может быть достаточно, например, уже ясно, что 100 000 хостов в сутки наш сайт не потянет.
Внимательно посмотрев на график времени отклика, можно увидеть полочку в его начале. В это время нагрузка росла, а реакция сервера не менялась, то есть ему было хорошо. Попробуем более подробно изучить этот диапазон нагрузок. Уменьшив Number of Threads и увеличив Ramp-Up Period, получаем такую картинку:
Видим, что сайту поплохело после 3 виртуальных юзеров и 150 запросов в минуту.
Для уверенности теперь есть смысл провести тест со статической нагрузкой. Ставим Number of Threads = 3, Ramp-Up Period= 0 (вводим потоки сразу) и смотрим, что получилось. Вроде все нормально, сайт реагирует живенько. Если хотим, снимаем несколько таких точек и на бумажке строим график. Эти цифры сильно достовернее, чем наблюдения по графику с динамической нагрузкой.
Заглянем теперь в Aggregate Report. Там для нас приготовлена статистика по URL-ам
(лучше всего смотреть после теста с большой, но не чрезмерной статической нагрузкой). Нас в первую очередь интересует колонка Average, среднее время отклика. Часто оказывется что есть несколько тяжелых страниц, которые в первую очередь и создают нагрузку на систему, и если их оттюнить, общая производительность многократно увеличивается (лучше всего начинать оптимизацию со страниц, которые по статистике вызываются часто, а отрабатывают долго). Справедливости ради надо отметить, что не всегда самые долгоиграющие страницы дают наибольший вклад в нагрузку, но чаще это так.
Пара слов об интерпретации полученных чисел: 3 виртуальных юзера, 150 запросов в минуту. Как эти величины соотносятся с реальными пользователями и, скажем, запросами страниц в сутки? Практически никак, мы не ставили себе цель смоделировать реального юзера. То, что мы имеем — относительная величина, на которую можно ориентироваться в процессе тюнинга. В данном случае 3 юзера получены при тестировании по списку урлов сайта, и «лог» не содержит картинок, css и прочих ресурсов. Так что 150 per minute как раз соответствуют настоящим запросам страниц в минуту. Если мы использовали реальный лог, то можно взять Aggregate Report, экспортировать его в csv (внизу есть кнопочка Save Table Data), повыкидывать из него все обращения к ресурсам, посчитать оставшиеся хиты и разделить на продолжительность теста.
В заключение хочется предупредить об одном недостатке описанного способа. Поскольку все виртуальные пользователи выполняют запросы в одном и том же порядке, эффективность кэширования на всех уровнях будет очень высокой. В реальности эффективность будет меньше, и это вносит в результаты наших исследований с трудом оцениваемую погрешность (кстати, надо будет написать сэмплер, который дергает строчки из лога в случайном порядке… если руки дойдут).
Но зато такой тест делается легко и быстро и обладает хорошей производительностью, так что для начала, имхо, в самый раз.
10 шагов для запуска тестирования производительности с Apache JMeter.

Давайте представим, что Вы — единственный тестировщик на проекте, а то и во всей компании. Компания подписала контракт на разработку продукта, в котором очень важна производительность, а у Вас нет ни малейшего представления о том, с чего начать. Инструментов представлено большое количество, и выбрать какой-либо не так уж просто. Сейчас я предлагаю ознакомиться с Apache JMeter и запустить первый тест за 10 простых шагов. Предварительно нужно убедиться что установлена Java 8 или Java 9 на устройстве, с которого будут запускаться тесты.

2. Распаковываем архив. Путь к распакованной папке не должен содержать кириллицу или пробелы. Открываем распакованную папку, заходим в папку /bin, там находим сам JMeter (jmeter.bat для Windows
jmeter.sh для Unix) и запускаем его. В результате будет представлен такой интерфейс:

3. Далее нам нужно добавить пользователей, которые будут ходить на страничку. Для этого снова выбираем тест план правым кликом и далее следуем в /Add/Threads (Users)/Thread Group. В итоге, в тест плане появляется следующий элемент:
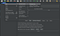
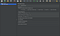
Дополнение: Можно выставить базовые параметры, указанные выше на любые значения, которые хочется испытать, но для начала рекомендую обойтись небольшими величинами, например, 10 пользователей и пару циклов. Выставление огромного количества пользователей в одном треде может проглотить все мощности вашего устройства и оно просто перезагрузится 🙂
4. Для запуска теста нужно указать инструменту адрес сервера, который будет подвержен нагрузке с типом запроса. Это делается через правый клик по уже добавленному Thread Group и выбор Add/Sampler/HTTP Request
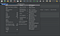
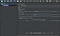
6. Тест нужно сохранить в папку /bin (там же, где лежит сам JMeter), далее, запустить терминал/командную строку и перейти в папку /bin, из которой на втором шаге запускали JMeter. Графическую оболочку лучше закрыть перед запуском теста. Запуск теста осуществляется командой:
7. Запускаем тест и ждём его завершения.

8. Далее, можно запустить JMeter командой jmeter (Windows) или sh jmeter.sh (Unix) отсюда же, из терминала/командной строки, или по старинке из папки /bin. После запуска нужно открыть сохранённый тест (в моём случае это doodles_test.jmx) и для него добавить отчёты. Самый простой отчёт — Summary Report, который добавляется через правый клик по Test Plan и, далее, Add/Listener/Summary Report. Listener’ы можно добавлять и в ходе настройки теста. Итак, Summary Report выглядит следующим образом:

9. Чтобы посмотреть результаты теста, нужно нажать Browse…, найти файлик с логами в формате *.jtl, который был прописан в шаге 6, и открыть его. В результате будет следующее:
10. Что можно понять из данного отчёта?
Заключение: В данной статье я постарался описать, пожалуй, один из самых простых способов начала работы с Apache JMeter. Причина проста — когда-то мне самому нужна была наглядная пошаговая инструкция для пробного запуска моего первого нагрузочного теста. Конечно, можно (и нужно!) изучать документацию по JMeter, смотреть видео инструкции, собирать информацию по форумам, но на это требуется немалое количество времени, которое у тестировщиков, зачастую, в дефиците 🙂
Приручаем JMeter
 Сегодня я хочу рассказать о замечательном инструменте, название которого вынесено в заголовок статьи. Разумеется, моей целью не является написание подробного руководства по Apache JMeter. В своей статье я хочу лишь зафиксировать ряд, на мой взгляд, не очевидных моментов, с которыми мне пришлось столкнуться в своей повседневной работе. Я надеюсь, что моя статья будет полезна (сразу предупреждаю, картинок будет много).
Сегодня я хочу рассказать о замечательном инструменте, название которого вынесено в заголовок статьи. Разумеется, моей целью не является написание подробного руководства по Apache JMeter. В своей статье я хочу лишь зафиксировать ряд, на мой взгляд, не очевидных моментов, с которыми мне пришлось столкнуться в своей повседневной работе. Я надеюсь, что моя статья будет полезна (сразу предупреждаю, картинок будет много).
Конечно, я не первый, кто пишет про JMeter на Хабре, но практически во всех предыдущих статьях, акцент делается на нагрузочное тестирование. Хотя это и основное применение JMeter, но только им его возможности не ограничиваются. Давайте, просто посмотрим, по каким протоколам может работать этот продукт:
Установка
Запись скрипта
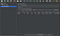
Это, пожалуй, самая эффектная возможность JMeter. Она уже описывалась ранее, но я повторюсь, поскольку в той статье речь шла об уже немного устаревшей версии. JMeter можно запустить в режиме proxy, таким образом, чтобы весь HTTP-трафик проходил через него. Все подробности взаимодействия будут автоматически записываться в выбранную Thread Group или Recording Controller. Для добавления новых узлов в дерево, просто нажимаем на правую кнопку мыши и выбираем требуемый тип из выпадающего меню:
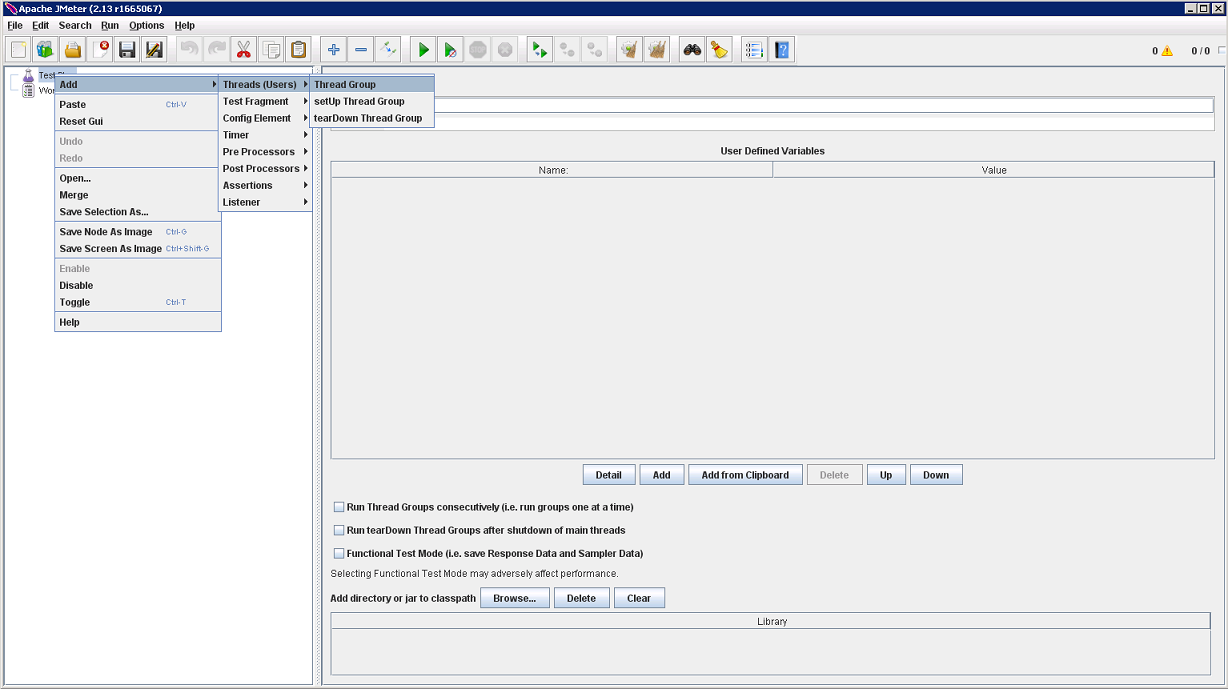
Thread Group, управляющая такими настройками как количество потоков, используемых для тестирования и количество запросов в тесте, находится в категории Treads (Users), а сам HTTP(S) Test Script Recorder в Non-Test Elements.
Я выделил на рисунке настройки, на которые следует обратить внимание. Порт возможно придётся изменить, если на 8080 уже что-то поднято. В сложных случаях, в Test Plan придётся добавить HTTP Cookie Manager и HTTP Authorization Manager. После нажатия кнопки Start, идём в настройки любимого браузера:
Взаимодействие с Яндекс, внезапно, оказывается очень непростым:
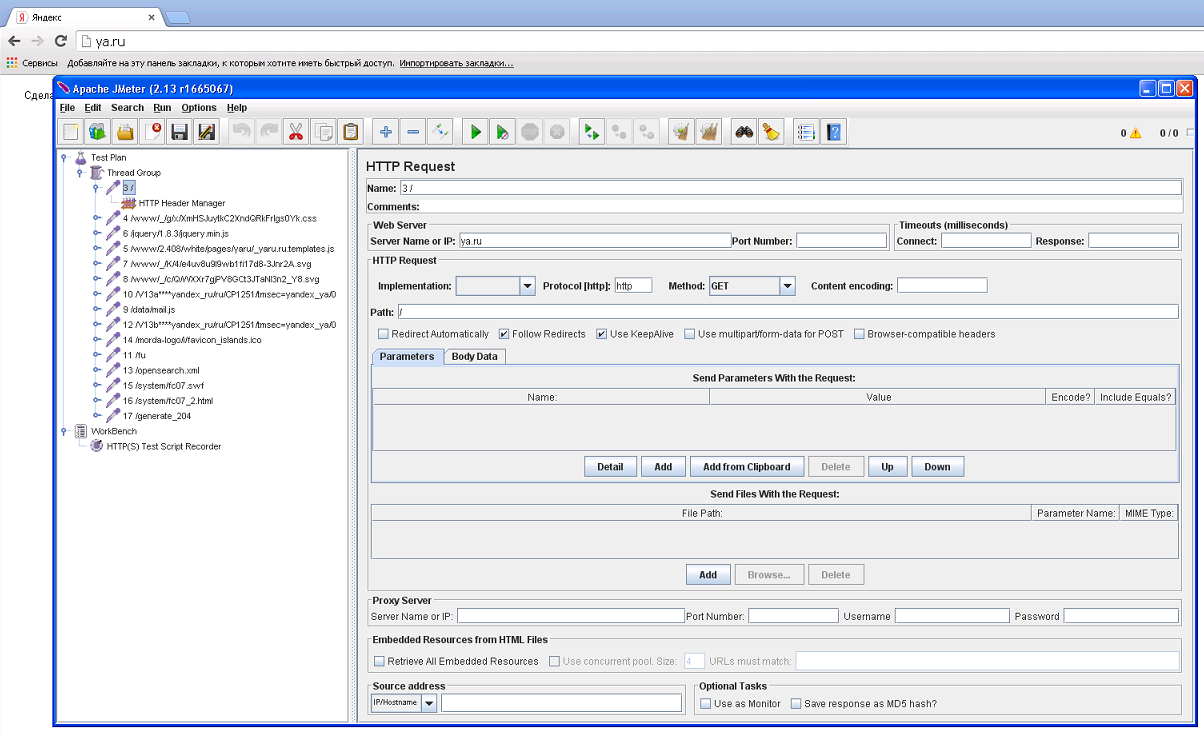
Полученные запросы (HTTP Request) вместе с их настройками (HTTP Header Manager) можно перенести в любое место скрипта, используя любимые всеми команды Copy&Paste (Drag&Drop тоже работает). Даже если вы твердо уверены в том, что происходит на вашем сайте, Script Recorder может быть очень полезен, для того чтобы узнать подробности. Кроме того, автоматическая генерация скриптов куда веселее чем вбивание их руками. Более подробно процесс записи скриптов описан в этой инструкции.
Переменные
Для чего-то мало-мальски серьёзного, нам потребуется возможность параметризации. Для примера, предположим, что нам требуется задать таймауты, в течение которых JMeter будет ожидать ответа сервера. Вбивать их заново в каждый HTTP Request, при любом изменении, было бы слишком утомительно. Заодно определим настройки HTTP Proxy (если он используется):

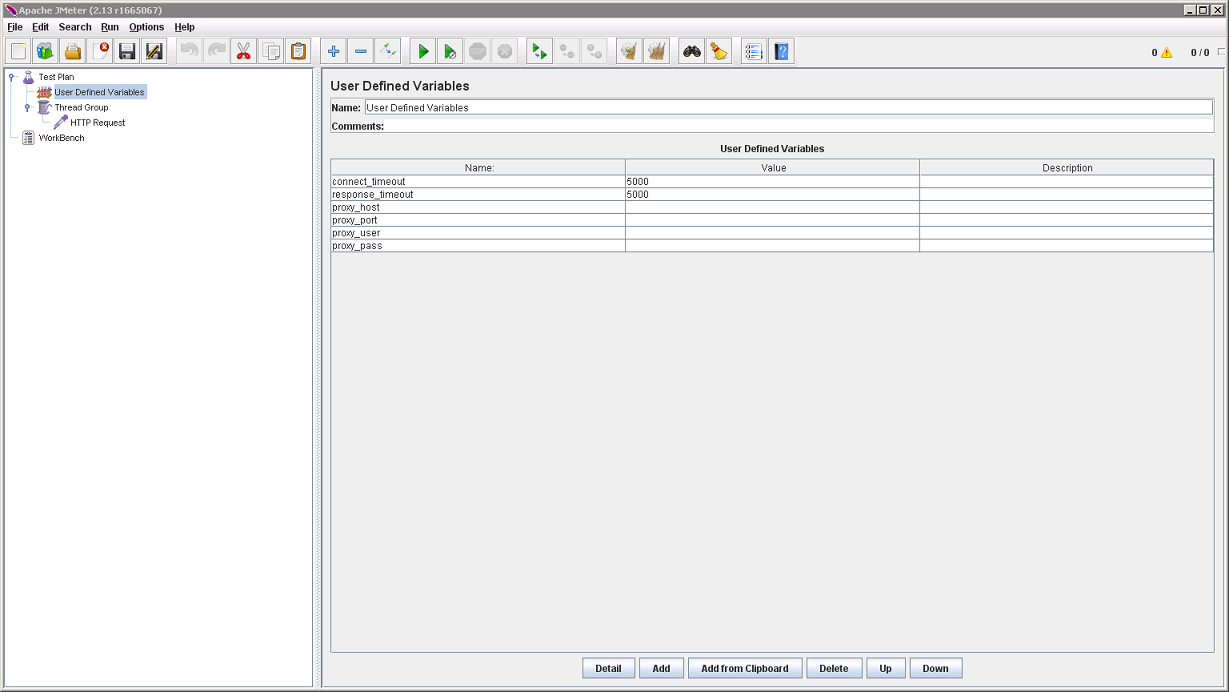
Пустые значения переменных проблемой не являются. В соответствующие настройки будут подставлены пустые строки, как того и требуется, в случае если HTTP Proxy не используется. Можно пойти ещё дальше и действительно разместить все HTTP-настройки в одном месте:
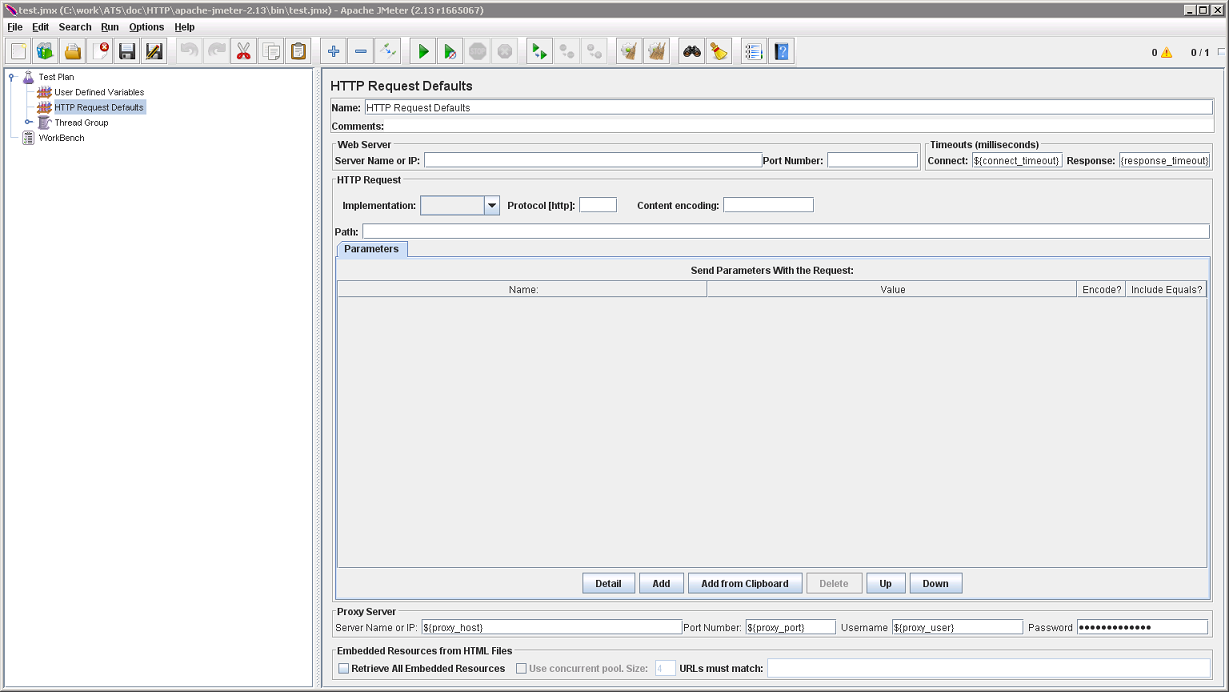
Элемент HTTP Request Defaults, также как и User Defined Variables расположен в категории Config Element.
Отладка
Теперь, было бы неплохо видеть, что происходит при выполнении сценария. Различного вида визуализаторы размещаются в категории Listener. Нам понадобится View Results Tree. Добавим его и запустим сценарий на выполнение командой Run/Start (Ctrl+R). Можно видеть, что ответ сервера также бывает непростым:

Такая картина наблюдается, если адрес редиректит нас на другую страницу и с этим может быть связана одна проблема. Если мы попытаемся анализировать ответ сервера (как это делать я покажу ниже), нам будет доступен лишь последний ответ (той страницы на которую произошёл redirect). Если ответ с предыдущей страницы нам также интересен, автоматический redirect придётся отключить. За это отвечает настройка Follow Redirects элемента HTTP Request. Разобрав ответ, мы сможем получить адрес целевой страницы и выполнить повторный запрос вручную.
Есть ещё один элемент, крайне полезный для отладки сценариев. Он находится в категории Sampler и называется Debug Sampler. Каждый раз, когда до него доходит управление, он выводит текущие значения всех переменных. Добавим его в Thread Group и запустим сценарий ещё раз (для того, чтобы очистить вывод предыдущего запуска, удобно использовать комбинацию клавиш Ctrl+E):
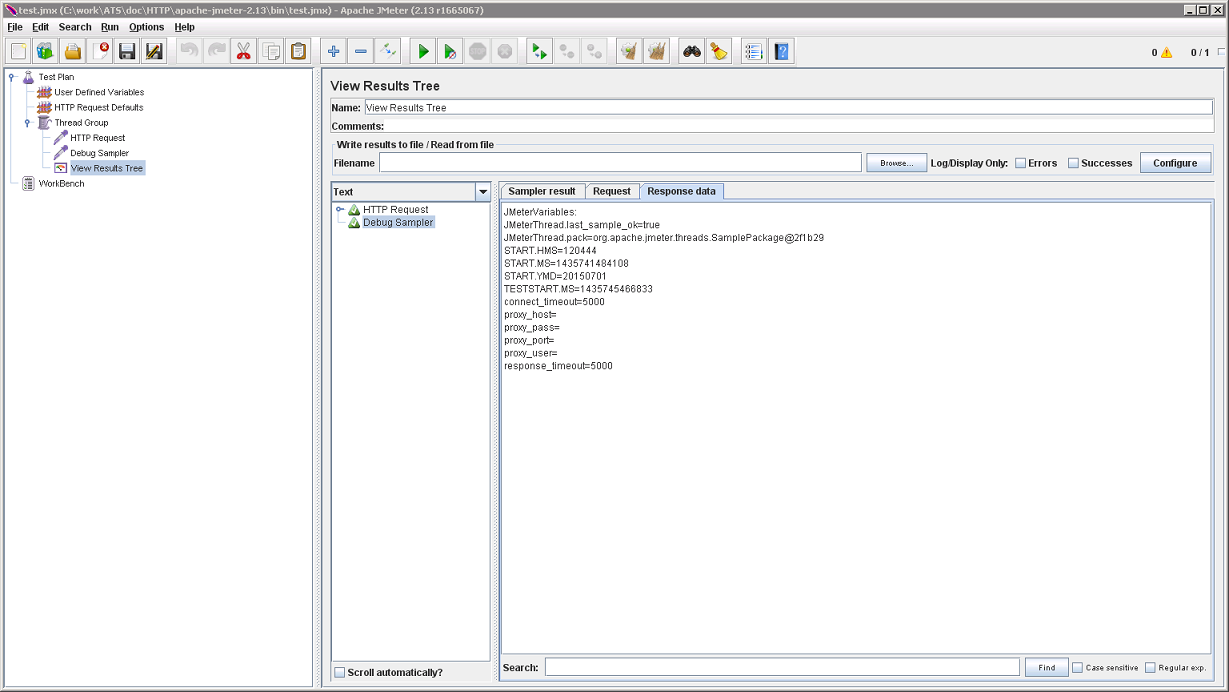
Все переменные как на ладони. Удобно.
JDBC Request
Этот Sampler открывает нам доступ в любую базу данных, поддерживающую протокол JDBC. Для начала, добавим в Test Plan конфигурационный элемент с настройками подключения к серверу БД (JDBC Connection Configuration):
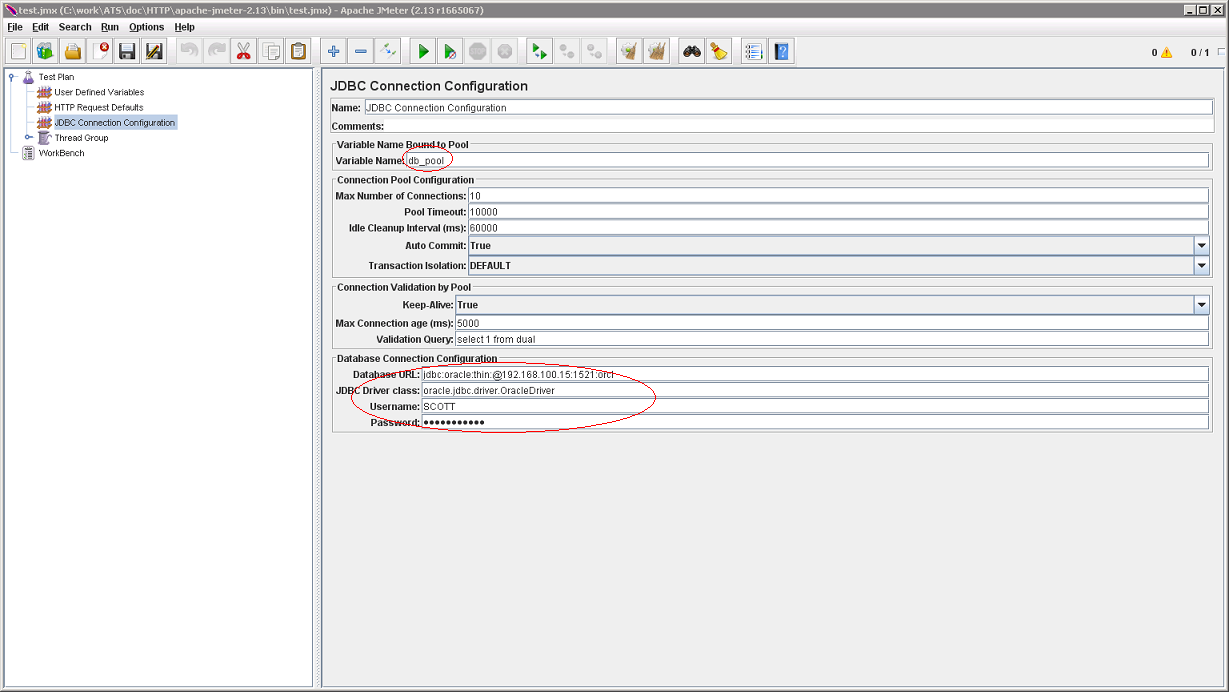
Помимо собственно настроек подключения к БД, здесь важно заполнить поле Variable Name. Это имя будет использоваться в JDBC Request (Sampler) для доступа к пулу сессий:
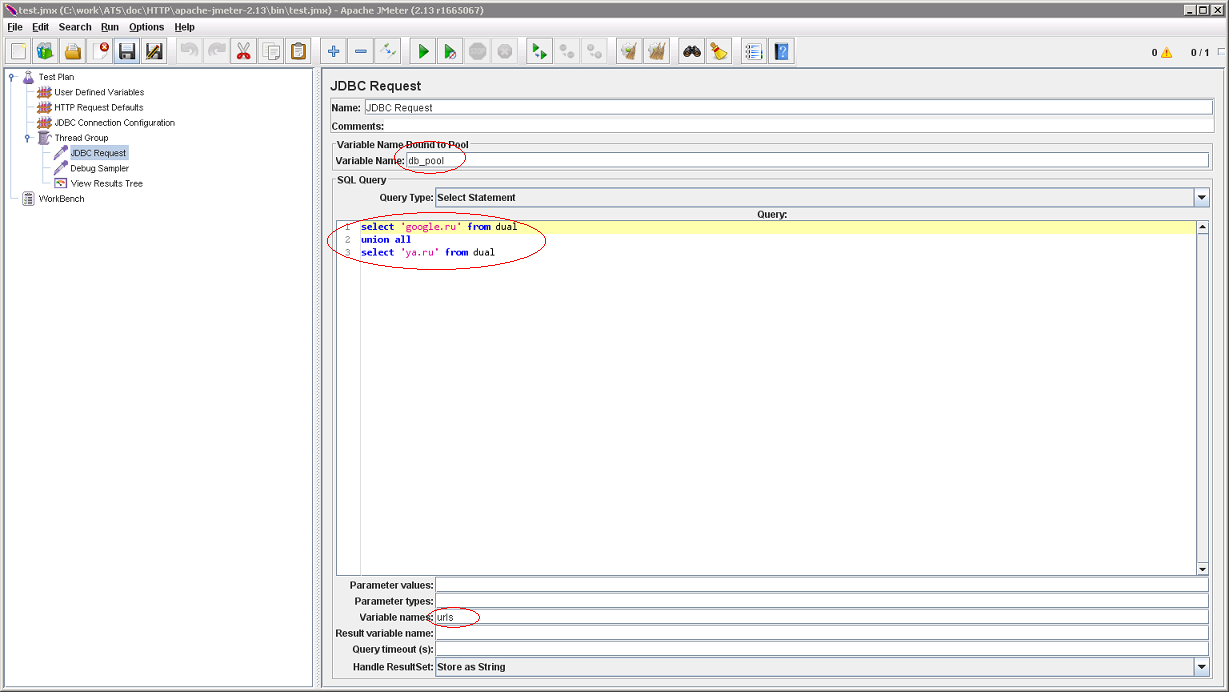
Если вам интересны результаты select-а, придётся заполнить Variable Names. Сам JMeter парсить SQL-запросы на предмет имён столбцов не умеет. Можно перечислять имена столбцов через запятую и пропускать столбцы, не давая им имени. Вставляем Debug Sampler и смотрим, что получилось:

Видим, что документация не врёт. Появились переменные urls_1 и urls_2 (количество строк, как и обещали, в urls_#). В этом месте, стоит соблюдать осторожность. Записи выбираются не по одной, а все сразу и прочитав >1000 строк можно легко отожрать слишком много памяти. Теперь, было бы неплохо обойти полученные адреса в цикле:

Да, именно вот так заковыристо. Набор переменных urls перебираем от 0 до $ и текущее значение помещаем в url. Сам ForEach Controller можно найти в категории Logic Controller. Внутри него создадим параметризованный HTTP Request. Запускаем, смотрим:
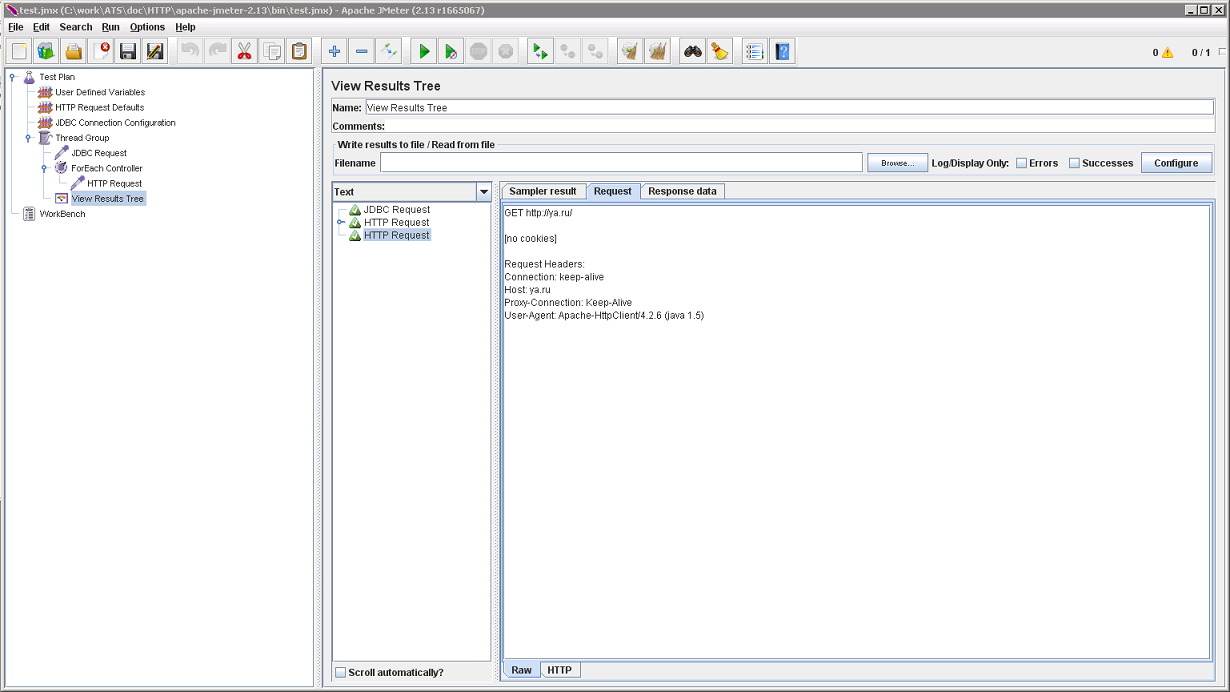
Регулярные выражения
Теперь, результаты обращений к Web-серверам хотелось бы проанализировать. Для этого, нам предоставлена вся мощь регулярных выражений. Regular Expression Extractor можно найти в Post Processors. Добавим его в HTTP Request и сконфигурируем:
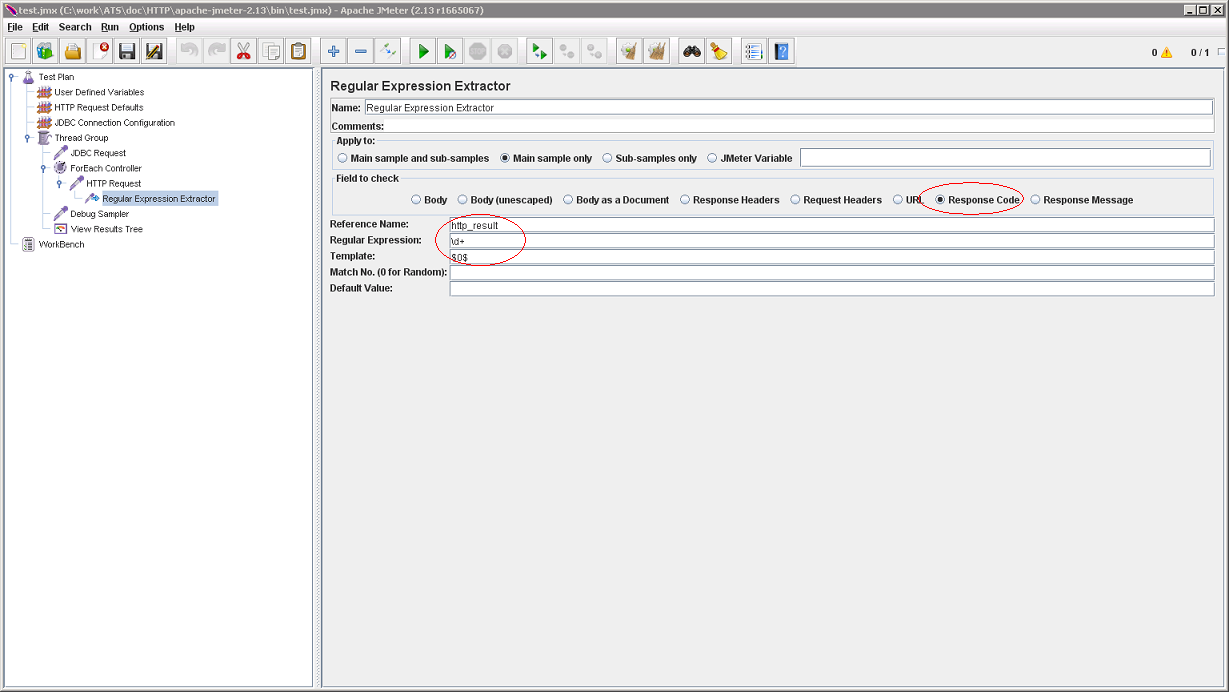
Здесь, нас интересует только код ответа по HTTP (но, по иллюстрации видно, что можно обрабатывать и содержимое ответа). Будем извлекать цепочку цифр (Regular Expression) и помещать результат применения шаблона (Template) в переменную http_result (Reference Name):
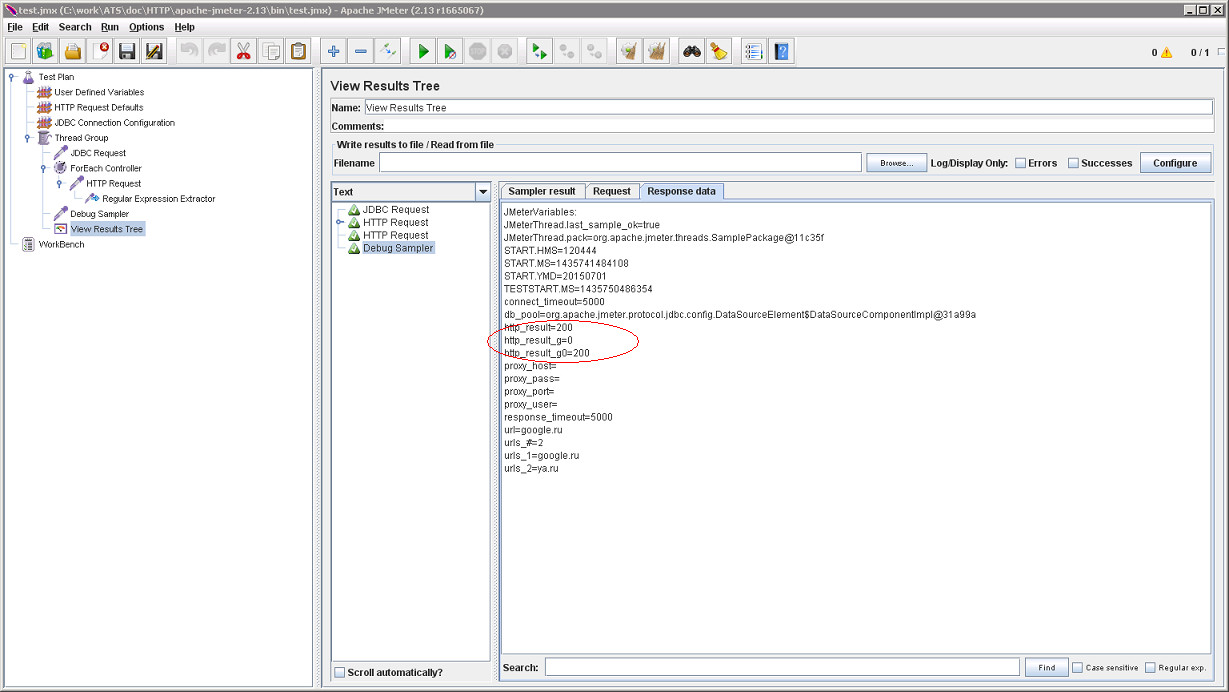
Как и ожидалось, получаем 200. Заодно, можно видеть, каким образом осуществляется захват в переменные регулярным выражением.
Что-то там внутри
Теперь, допустим, что нас интересует время, в течение которого выполнялся HTTP-запрос. И интересует оно нас не просто для статистики, а мы его хотим как-то использовать в сценарии (например сложить в БД). С этой задачей поможет справиться BeanShell. Конкретно, мы используем его Pre — и PostProcessor-ы.

В первом будем получать timestamp:
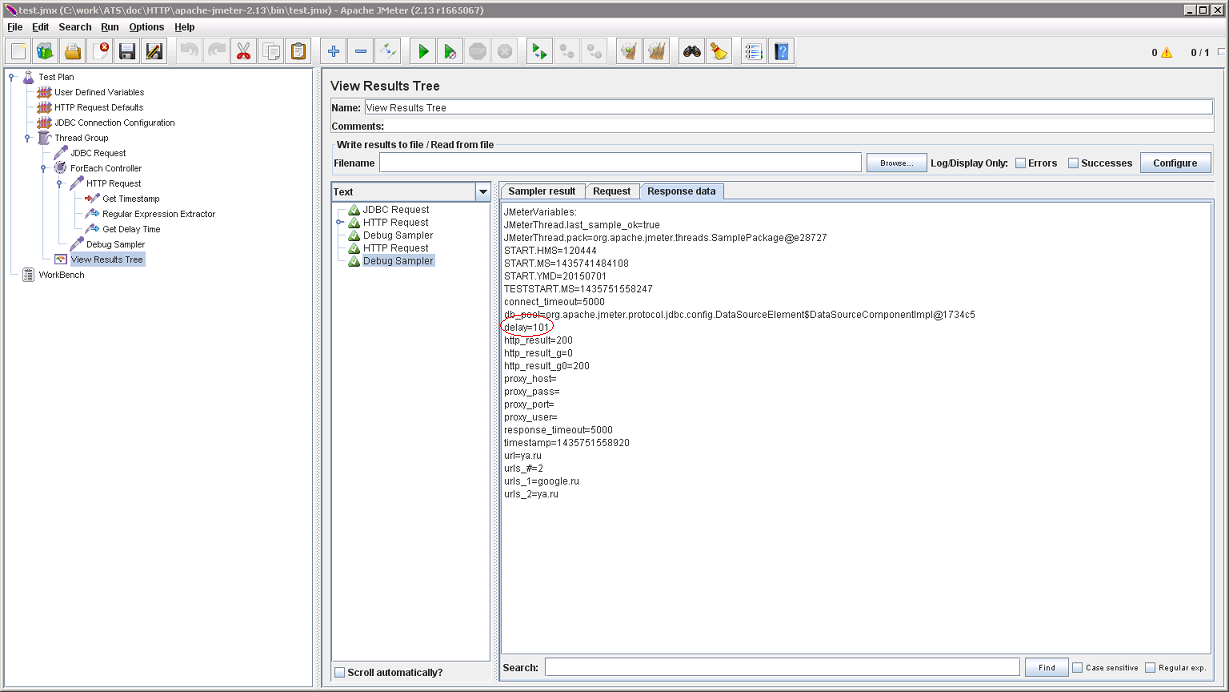
А во втором, получать с его помощью временную задержку:
В общем, это тоже работает:
Но здесь следует сделать важное замечание. Поскольку, в настоящий момент, я занимаюсь не нагрузочным тестированием, производительность этой конструкции для меня не очень важна. Если в вашем случае это не так, стоит ознакомиться со следующей статьёй.
Запуск
Если бы не было этой возможности, не стоило бы и весь этот разговор заводить. В случае нагрузочного тестирования, сценарий можно запускать из GUI, нет проблем. Но если нас интересует автоматизация, необходимо уметь запускать его молча (например по cron-у). Разумеется такая возможность тоже есть:
Сохраняем сценарий в файл с расширением jmx (внутри это XML) и запускаем эту команду. Сценарий отрабатывает без запуска GUI и заодно пишет результаты своей работы в лог. Всё просто и удобно.