Применение параметра «Предполагать целостность данных» в Power BI Desktop
При подключении к источнику данных с помощью DirectQuery можно установить флажок Предполагать целостность данных, что позволит создавать более эффективные запросы к источнику. У этой функции есть некоторые требования к базовым данным, и она доступна только при использовании DirectQuery.
Если флажок Предполагать целостность данных установлен, в запросах к источнику данных используются инструкции INNER JOIN, а не OUTER JOIN. Они повышают эффективность запросов.
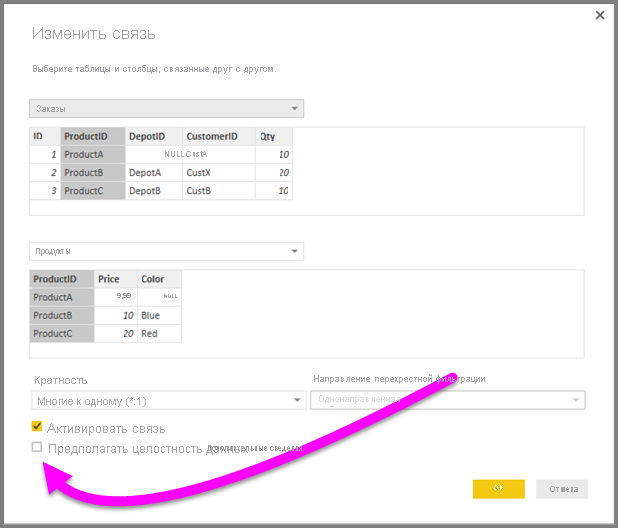
Требования для использования функции «Предполагать целостность данных»
Это дополнительная функция. Она доступна только при подключении к данным с помощью DirectQuery. Чтобы функция Предполагать целостность данных работала правильно, необходимо выполнить следующие условия:
В этом контексте столбец Из выступает в роли многих в связи типа один ко многим или же является столбцом первой таблицы в связи типа один к одному.
Пример использования функции «Предполагать целостность данных»
В примере ниже показано, как работает функция Предполагать целостность данных, когда она используется в подключениях к данным. Приложение подключается к источнику данных, который содержит таблицы Заказы, Товары и Склады.
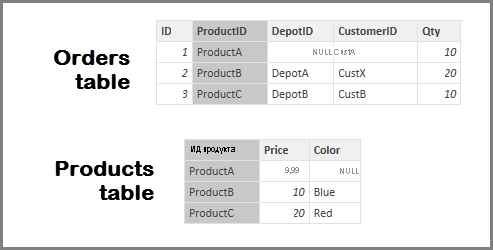
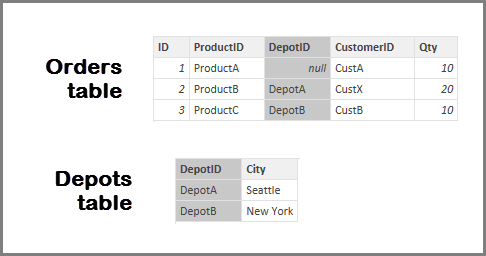
На рисунке ниже целостность данных между столбцами Заказы[КодСклада] и Склады[КодСклада] не существует, так как в столбце КодСклада для некоторых заказов указано значение Null. Поэтому флажок Предполагать целостность данных устанавливать не нужно.
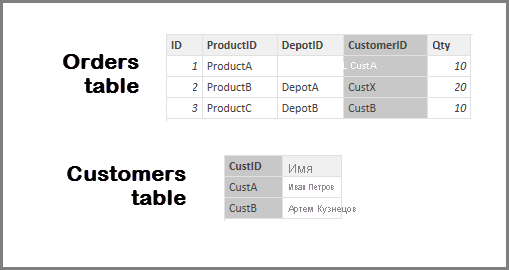
На рисунке ниже целостность данных не существует между столбцами Заказы[КодКлиента] и Клиенты[КодКлиента] : в столбце КодКлиента есть значения (в данном случае — КлиентX), которых нет в таблице Клиенты. Поэтому флажок Предполагать целостность данных устанавливать не нужно.
Установка флажка «Предполагать целостность данных»
Чтобы активировать эту функцию, установите флажок Предполагать целостность данных, как показано на рисунке ниже.
Когда флажок установлен, выполняется проверка на отсутствие значений Null и несовпадающих строк. Но если значений очень много, такая проверка не гарантирует отсутствие проблем с целостностью данных.
Кроме того, проверка выполняется на этапе редактирования связей, и все будущие изменения в данных в ней не учитываются.
Что произойдет, если неправильно установить флажок «Предполагать целостность данных»
Если установить флажок Предполагать целостность данных, то при наличии проблем с целостностью ошибки возникать не будут. Однако это приведет к очевидной несогласованности в данных. Например, связь с таблицей Склады из примера выше приведет к следующему:
Дальнейшие действия
Дополнительные сведения о DirectQuery.
Дополнительные сведения о связях в Power BI.
Главная особенность SQL-технологий наличие у сервера СУБД специальных средств контроля целостности данных, не зависящих от клиентских программ и привязанных непосредственно к таблицам. Т.е. принципиально не важно, каким образом осуществляется доступ к базе данных: через SQL-консоль, через ODBC-драйвера из приложения Windows, через WWW-connector из Internet-браузера или через DBI-интерфейс Perl. В любом из этих случаев, за контролем целостности данных следит сервер, и при нарушении правил целостности данных сервер известит клиента об ошибке.
К структурам контроля целостности данных относятся ограничители (constraint), которые привязаны к столбцам и триггеры (trigger), которые могут быть привязаны как к столбцам, так и к строкам в таблице.
Ограничители это элементарные проверки или условия, которые выполняются для операций вставки и модификации значения столбца. Если данная проверка не проходит или условие не выполняется, то вставка или модификация отменяется, а в программу клиента передается ошибка.
SQL-серверы, как правило, поддерживают следующие ограничители.
SQL-технология позволяет на уровне столбца задавать домены значений, т.е. строго определенные наборы или диапазоны значений, для помещаемых в столбец данных. В частности можно реализовывать ограничения ссылочной целостности (referential integrity constraint) и проверки фиксированного условия. Ограничение ссылочной целостности не позволяет значениям из столбца одной таблицы принимать значения кроме как из присутствующих в столбце другой таблицы. Это делается при помощи ограничителей FOREIGN KEY (внешний ключ) и REFERENCES (указатель ссылки). Таблица, содержащая FOREIGN KEY, считается родительской таблицей. Таблица, содержащая REFERENCES, считается дочерней таблицей. Внешний ключ и указатель ссылки могут находиться в одной таблице, т.е. родительская таблица одновременно является дочерней.
Для использования ограничений ссылочной целостности должны выполняться некоторые условия. В частности, родительская и дочерняя таблицы должны находиться в пределах одного аппаратного сервера базы данных, они не могут находиться на различных узлах распределенной базы данных. Столбцы, участвующие в отношении ограничения ссылочной целостности обязаны иметь один и тот же тип данных.
Ограничения ссылочной целостности используются при каскадном удалении, т.е. при удалении записи в родительской таблице удаляются все записи с указанным ключом из дочерних таблиц, и наоборот при запрете удаления/модификации, т.е. при наличии зависимых записей в дочерних таблицах, значение ключа записи в родительской таблице нельзя удалить или модифицировать.
Обычно ограничители задаются при создании таблиц. Но в дальнейшем их можно изменять, удалять или временно запрещать при помощи соответствующих команд СУБД.
Некоторые типовые применения триггеров:
В случае необходимости триггеры можно запрещать, а затем разрешать. Запрещение триггеров применяется обычно при массовых загрузках данных в таблицы извне, с целью уменьшения времени загрузки. Понятие триггера как выполнение кода по событию в том же Oracle используется весьма широко. В частности, оно является основным при разработке клиентских программ при помощи SQL*Forms. Триггеры пишутся на процедурных расширениях SQL.
Обработка данных в многопользовательской СУБД.
Конкуренция в доступе к данным означает, что каждый из пользователей независим от остальных пользователей в потребности обработки данных. Система, во избежание порчи данных, самостоятельно устанавливает очередность работы с данными для пользователей. В случае необходимости пользователи могут ожидать своей очереди для работы с данными. Одной из главной целей многопользовательской СУБД является максимальное уменьшение этого времени ожидания до такой степени, чтобы оно (в идеале) стало незаметным для пользователя.
Кроме того, сервер СУБД должен предотвращать взаимно разрушающие манипуляции с данными нескольких пользователей при их одновременной работе. Например, если система не предусматривает такую возможность, то менеджеры принимающие заказы от клиентов на поставку товара, и выполняющие их резервирование на складе, могут зарезервировать товара больше чем фактически имеется в наличии. В этом случае обеспечен неприятный разговор с клиентом, заказ которого будет впоследствии отменен.
Более неприятная ситуация возможна в банке: если одновременно исполняется несколько клиентских платежных поручений с одного счета, то при неконтролируемом списании с клиентского счета возможен отрицательный остаток, что недопустимо.
Контроль нужен также в системах резервирования билетов на транспорте, чтобы билет на одно и то же место не был продан разными кассирами разным пассажирам.
Несмотря на различия в реализации, серверы СУБД используют общие способы управления данными и доступом к ним.
Атомарность SQL-выражений при работе с данными.
Под атомарностью выражения понимается неизменность (фиксация во времени) набора данных, с которыми это выражение работает на всем протяжении своего исполнения. Т.е. если мы выполняем оператор UPDATE над определенной таблицей, то состояние таблицы на момент начала выполнения операции фиксируется во времени и не изменяется до конца выполнения оператора. Этот набор данных для текущего выполняемого выражения не может быть изменен другим пользователем или даже другой сессией этого же пользователя, которая пытается выполнить операцию модификации этих же данных в этой же таблице.
Распараллеливание операций.
Типовые операции с таблицей в базе данных состоят из многих однотипных операций, например оператор UPDATE, который модифицирует 5000 строк в таблице, по своей сути состоит из 5000 операций, каждая из которых может быть выполнена независимо. В связи с этим такие операторы очень хорошо распараллеливаются при использовании многопроцессорных систем. Это позволяет выровнять нагрузку в системе между разными процессорами, при том условии что СУБД умеет работать в многопроцессорной конфигурации, и уменьшить время ответа системы.
Обеспечение максимальной производительности.
С целью сокращения времени различных пользователей на манипуляции с данными используется ряд следующих методов. Их работа находится на уровне, скрытом даже от программиста СУБД, но о них стоит упомянуть т.к. они иллюстрируют серьезные различия с xBase-технологией.
Строго говоря, эта информация справедлива лишь в отношении Oracle, но другие СУБД используют подобные принципы.
Данные приемы позволяют существенно уменьшить время ожидания ответа системы и увеличить ее производительность.
Транзакции
Например, мы пытаемся модифицировать таблицу при помощи оператора UPDATE. В одном из столбцов этим оператором устанавливается недопустимое значение с точки зрения правил целостности для этой таблицы. Срабатывание ограничителя приведет к тому, что сервер СУБД не позволит выполнить такую модификацию и известит нас ошибкой, а механизм контроля транзакций вызывает отмену всего выполняемого выражения и производит откат к предыдущему состоянию таблицы, сохраняя, таким образом, целостность и непротиворечивость данных. В данном примере транзакция работает с одним SQL-выражением. В случае если выражений несколько, то откатывается результат работы всех выражений составляющих единую транзакцию.
Если происходит явное сохранение изменений в системе (по команде COMMIT) или неявное сохранение изменений (по завершению группы SQL-выражений, формирующих транзакцию или по завершению сеанса пользователя), то все изменения произошедшие с момента начала транзакции вносятся в систему, и информация о данной транзакции удаляется из журнала.
Для облегчения управления системой в режиме регистрации транзакций существует возможность задания так называемых промежуточных точек сохранения. Промежуточная точка сохранения по команде SAVEPOINT явно помечает состояние системы и предоставляет возможность восстановления состояния БД на момент ее сохранения по команде ROLLBACK. В данном случае ROLLBACK откатывает систему к указанной точке. Обычно промежуточных точек сохранения для одного пользователя может быть несколько.
Данная схема справедлива для Oracle, где транзакция начинается с выполнением первого оператора, прочие сервера могут работать по-другому. Например в Informix DS, транзакция начинается явно, при помощи команды BEGIN WORK.
В SQL-бочке меда есть своя ложка дегтя. Для всех SQL-серверов использующих журнальный режим регистрации транзакций существует проблема, так называемых «длинных» транзакций. Это транзакции, которые затрагивают очень большой объем данных (сопоставимый с количеством свободного места на дисках) и в этом случае журналы регистрации транзакций могут переполниться. Если их рост ничем неограничен, то они могут израсходовать у ОС всю доступную дисковую память, что не есть хорошо, т.к. операционная система и сервер СУБД в этом случае остаются в непредсказуемом состоянии. Если их рост ограничен, то при переполнении журналов СУБД выдает соответствующую ошибку и операция откатывается. Чтобы избежать таких ситуаций программист должен разделить длинную транзакцию на короткие транзакции.
Блокировки.
Для того чтобы пользователи не искажали взаимно используемые данные, сервер СУБД, при многопользовательской работе, использует механизм блокировок. Блокировки по аналогии с базами данных на основе файлов могут быть как разделяемые, так и исключительные. Блокировки могут устанавливаться как на таблицу целиком, так и на строку в таблице. Аналогично в xBase-технологиях: блокировки могут устанавливаться как на xBase-файл, так и на запись в xBase-файле.
Блокировки связаны с транзакциями. Если выполняется отмена транзакции, то снимаются все связанные с этой транзакцией блокировки.
Многие блокировки выполняются неявно для пользователя, они выставляются, например, операторами UPDATE, INSERT. Существуют явные операторы задания блокировок, например, LOCK TABLE или операторы, имеющие клаузы блокировки, например SELECT : FOR UPDATE. Соответственно есть операторы и для снятия блокировок.
Многие SQL-серверы имеют специальные способы обнаружения и предотвращения взаимных блокировок (deadlocks), которые могут занимать ресурсы СУБД на неопределенное время.
Способы, которыми обеспечиваются блокировки, зависят от реализации сервера, и описываются в его документации. Виды блокировок также зависят от используемого сервера. В Informix существуют, т.н. promotional locks, это означает, что если клиентский процесс не может блокировать в исключительном режиме ресурс, то такая блокировка ставится в очередь и ей предоставляется ресурс после снятия текущей исключительной блокировки другого процесса. Oracle7 так не делает, если он не может установить исключительную блокировку в течение указанного сервером времени, то клиент извещается об ошибке.
Принципы поддержки целостности в реляционной модели данных
быть предусмотрены средства и методы, которые позволят нам обеспечивать динамическое отслеживание в базе данных согласованных действий, связанных с согласованным изменением информации. Именно этим вопросам и посвящена данная лекция.
Общие понятия и определения целостности
Поддержка целостности в реляционной модели данных в ее классическом понимании включает в себя 3 аспекта.
Во-первых, это поддержка структурной целостности,которая трактуется как то, что реляционная СУБД должна допускать работу только с однородными структурами данных типа «реляционное отношение «. При этом понятие «реляционного отношения» должно удовлетворять всем ограничениям, накладываемым на него в классической теории реляционной БД (отсутствие дубликатов кортежей, соответственно обязательное наличие первичного ключа, отсутствие понятия упорядоченности кортежей).
| А | В | Not A | A & B | 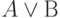 |
|---|---|---|---|---|
| TRUE | TRUE | FALSE | TRUE | TRUE |
| TRUE | FALSE | FALSE | FALSE | TRUE |
| TRUE | Null | FALSE | Null | TRUE |
| FALSE | TRUE | TRUE | FALSE | TRUE |
| FALSE | FALSE | TRUE | FALSE | FALSE |
| FALSE | Null | TRUE | FALSE | Null |
| Null | TRUE | Null | Null | TRUE |
| Null | FALSE | Null | FALSE | Null |
| Null | Null | Null | Null | Null |
Ссылочная целостность обеспечивает поддержку непротиворечивого состояния БД в процессе модификации данных при выполнении операций добавления или удаления.
Принципы семантической поддержки целостности как раз и позволяют обеспечить автоматическое выполнение тех условий, которые перечислены ранее.
Выделяются следующие виды декларативных ограничений целостности:
Задание значения по умолчанию означает, что каждый раз при вводе новой строки в отношение, при отсутствии данных в указанном столбце этому атрибуту присваивается именно значение по умолчанию. Например, при вводе новых книг разумно в качестве значения по умолчанию для года издания задать значение текущего года. Например, для MS Access 97 это выражение будет иметь вид:
Здесь NOW() — функция, возвращающая значение текущей даты, YEAR(data) — функция, возвращающая значение года указанной в качестве параметра даты.
Для MS Access 97 это выражение будет выглядеть следующим образом:
В СУБД MS SQL Server7.0 значение по умолчанию записывается в качестве «бизнес-правила». В этом случае будет использоваться выражение, в котором явным образом должно быть указано имя соответствующего столбца, например:
Здесь GETDATE() — функция MS SQL Server7.0, возвращающая значение текущей даты, YEAR_PUBL — имя столбца, соответствующего году издания.
Да, это действительно легче, тем более что в процессе работы схема базы данных разрастается и начинает содержать более сотни отношений, и задача нетривиальная — найти все отношения, в которых ранее установлено это ограничение и исправить его.
Одним из основных правил при разработке проекта базы данных, как мы уже упоминали раньше, является минимизация избыточности, а это означает, что если возможно информацию о чем-то, в том числе и об ограничениях, хранить в одном месте, то это надо делать обязательно.
Декларативные ограничения целостности относятся к ограничениям, которые являются немедленно проверяемыми. Есть ограничения целостности, которые являются откладываемыми. Эти ограничения целостности поддерживаются механизмом транзакций и триггеров. Мы их рассмотрим в следующих лекциях.
Целостность данных. Ограничения целостности.
А что ещё (с надеждой на безошибочность описания) можно почерпнуть из документации об Ограничениях целостности в Oracle? Я постарался выписать различные терминологические и функциональные особенности Ограничений целостности как отдельных типов объектов БД Oracle без углубления в синтаксис и подробности их использования. Многое для меня оказалось новым, не буду скрывать.
Начнём с самого начала – Oracle9i Database Concepts Release 2 (9.2). В документации выделяется понятие «Целостность данных» ( Data Integrity ), которое связывается с выполнением бизнес-правил, сопряжённых с БД. Data Integrity делится на пять типов правил, часть из которых обеспечивается «Ограничениями целостности» ( Integrity Constraints ) СУБД Oracle :
2. уникальные значения – ограничения уникального ключа;
3. значения первичного ключа – ограничения первичного ключа;
4. правила ссылочной целостности – ограничения внешнего ключа (или «ограничения ссылочной целостности» – в документации Oracle встречаются оба названия);
(Здесь слева от тире представлено правило «Целостности данных», а справа – тип «Ограничений целостности», реализующий это правило)
Четвёртый тип правил «Целостности данных» является составным, и обеспечивается «Ограничениями целостности» лишь частично:
1. выставление в NULL зависимых данных при удалении справочных данных;
2. каскадное удаление зависимых данных при удалении справочных данных;
Оставшиеся существующие подтипы четвёртого пункта «Целостности данных»:
o выставление в NULL зависимых данных при изменении справочных данных;
o каскадное изменении зависимых данных при изменении справочных данных;
o выставление в значение по умолчанию зависимых данных при изменении или удалении справочных данных;
Те типы правил «Целостности данных», которые нельзя обеспечить с помощью существующих типов «Ограничений целостности», можно реализовать с помощью триггеров. Впрочем, любые типы правил «Целостности данных» можно организовать посредством триггеров, только этот путь более сложен и менее производителен.
Далее для краткости и в силу привычки буду использовать названия «Ограничений целостности» в английском варианте (соотнесение с вышеупомянутыми русскими названиями, на мой взгляд, очевидно), а вместо «Ограничения целостности» писать просто Ограничения.
При создании UNIQUE Key Constraints или PRIMARY Key Constraints неявно создаётся уникальный индекс по тем полям таблицы, на которые накладывается данное Ограничение. Однако, если некий (неважно – уникальный или неуникальный) индекс по полям ключа уже используется, то будет использоваться именно он вместо неявного создания нового. При удалении этих Ограничений будут удаляться и индексы. Уникальные Ограничения, созданные с атрибутом DEFERRABLE (см. ниже) всегда используют неуникальные индексы. При удалении таких Ограничений неуникальные индексы остаются.
Все перечисленные Ограничения, реализованные в Ora c le, допускают их нарушение на уровне оператора, то есть сначала оператор будет полностью выполнен (пускай он коснётся хоть миллиона строк), а потом начнётся проверка Ограничений. Хотя, возможна отложенная проверка Ограничений– до завершения транзакции (о чём речь далее).
Режим SET CONSTRAINTS.
Выполнение оператора SET CONSTRAINTS … IMMEDIATE перед самым завершением транзакции позволяет определить успешность предстоящего COMMIT’а и избежать лишних откатов.
С помощью операторов CREATE TABL E или ALTER TABLE можно задавать состояние каждого Ограничения на уровне таблицы, используя следующие выражения:
… и немного об особенностях применения:
· выражение ENABLE подразумевает ENABLE VALIDATE ;
· выражение DISABLE подразумевает DISABLE NOVALIDATE ;
· VALIDATE и NOVALIDATE ничего не подразумевают в отношении ENABLE и DISABLE (скажем так, они являются зависимой частью выражения при ENABLE и DISABLE );
· про создание и удаление индексов уже упоминалось;
· при изменении состояния из NOVALIDATE в VALIDATE выполняется проверка всех имеющихся в таблице данных, что может занять очень много времени. Наоборот, при приведении состояния Ограничения из VALIDATE в NOVALIDATE просто «забывается», что имеющиеся данные когда-то соответствовали Ограничению;
· перевод одиночного ограничения из состояния ENABLE NO VALIDATE в состояние ENABLE VALIDATE не блокирует чтения, записи или другие DDL операции, они могут быть выполнены параллельно.
И последние важные замечания.
1.5. Обеспечение целостности данных
Во время проектирования базы данных вы должны заботится о целостности данных. Правильная структура таблиц позволяет защитить данные от нарушения связей и внесения неверных значений. Вы должны определить наилучший путь обеспечения целостности данных. Целостность данных основывается на стойкости и точности данных, которые хранит база данных.
Существуют различные типы целостности данных:
Все операторы, необходимые для реализации всех уровней целостности нам уже знакомы. Я специально вынес рассмотрение теории обеспечения целостности после того, как мы узнали средства. Знание операторов упростит понимание теоретических данных.
Как мы можем гарантировать целостность данных? Для этого существует два способа: описанная целостность данных и предшествующая целостность данных. Пока эти понятия не понятны, но после того, как вы увидите, какими средствами достигается тот, или иной способ, все встанет на свои места.
Описанная целостность данных – вы объявляете критерии, которые данные должны содержать как часть описания объекта и после этого SQL Server автоматически гарантирует, что данные соответствуют критериям. Уже можно догадаться, что такая целостность обеспечивается с помощью ограничений CHECK, DEFAULT и внешнего ключа.
Описанная целостность является частью объявления базы данных, и объявляется с помощью ограничений, которые вы можете назначить колонкам и таблицам напрямую.
Предшествующая целостность данных – это программа, которая определяет критерии, которым должны соответствовать данные. Этот метод обеспечивается с помощью процедур и триггеров (о них мы поговорим в главе 3), которые могут выполняться на сервере или с помощью кода программ в клиентском приложении.
Вы должны минимизировать использование этого метода для упрощения бизнес логики и ошибок, но иногда без триггера не возможно гарантировать, что таблицы будут содержать нужные или разрешенные значения.
Ограничение – это основной метод обеспечения целостности данных. В этой секции описывается, как определить, какой тип ограничения использовать, какой тип данных и для какого ограничения использовать, и как определить ограничения.
Ограничение – метод ANSI стандарта обеспечения целостности данных. Каждый тип целостности данных – доменный, табличный и ссылочный обеспечиваются отдельным типом ограничений. Ограничения обеспечивают правильность данных введенных в поле, и какие отношения обеспечиваются между таблицами. Следующая таблица описывает различные типы ограничений:
Как мы уже знаем, ограничения могут создаваться во время создания таблицы (CREATE TABLE) или редактирования (ALTER TABLE). Если ограничение назначается отдельному полю, оно называется ограничения уровня поля. Если ограничение ссылается на несколько полей, оно называется ограничением уровня таблицы, даже если оно ссылается не на все колонки таблицы.
Имена ограничений должны быть уникальными для базы данных. Если не указывать имена, то сервер сгенерирует значение самостоятельно, но как мы видели в разделе 1.4.4 сгенерированное значение слишком сложное и не отражает сути происходящей проверки. Поэтому, я рекомендую всегда указывать имена самостоятельно и так, чтобы оно отражало суть происходящей проверки и таблицы, в которой происходит проверка.
Теперь рассмотрим уже знакомые нам операторы ограничений, только с точки зрения обеспечения целостности данных. В некоторых из них мы увидим что-то новое, а в некоторых просто закрепим пройденный материал.
1.5.1. DEFAULT
Ограничение DEFAULT помещает значение в колонку, когда оно не было указано в операторе INSERT. Оно относится только к оператору добавления записи (INSERT) и не срабатывает во время изменения полей (оператор UPDATE). Таким образом, данное ограничение не гарантирует, что поле содержит значение. Пользователь может добавить строку и потом с помощью UPDATE обнулить содержимое поле со значением по умолчанию.
Таким образом, DEFAUL является самым простым и быстрым по скорости выполнения методом обеспечения целостности, но не является гарантом. Необходимы дополнительные средства, например, ограничение на диапазон вводимых значений или триггер. Например, в листинге 1.10, помимо значения DEFAULT мы создаем ограничение, которое не позволяет записывать в поле нулевые значения, что защитит нас от возможности записи в поле NULL даже при обновлении данных:
Листинг 1.10. Создание таблицы с ограничением DEFAULT и CHECK
В данном примере мы устанавливаем сразу два ограничения на поле «iID» таблицы TestTable. Первое DEFAULT устанавливает значение по умолчанию, если во время добавления записи для поля «iID» не было указано значения. Вторая проверка CHECK не позволит сделать поле нулевым с помощью операции обновления записей.
После этого в листинге показаны примеры добавления и обновления записи. Во время обновления мы пытаемся записать в поле значение NULL. В ответ на это сервер вернет нам ошибку и сообщит, что сработало ограничение check_iID.
1.5.2. CHECK
Ограничение CHECK ограничивает данные, которые пользователь может ввести в определенную колонку указанными значениями. Следующий пример добавляет ограничение, чтобы гарантировать, что день рождения соответствует определенному промежутку времени:
В данном примере создается таблица для хранения имен и дат рождений «dBirthDate». Дата рождения не может быть меньше 1900. Людей, которым более 105 лет на земле осталось не так много, и вероятность того, что такие люди попали к нам в базу стремится к нулю.
Как мы уже знаем, ограничение CHECK срабатывает не только при вставке данных, но и при обновлении.
Мы еще не говорили про запросы выборки данных и подзапросы, но необходимо заметить, что в ограничении CHECK нельзя использовать подзапросы.
1.5.3. Ключи
Ограничение PRIMARY KEY определяет первичный ключ таблицы, который уникально идентифицирует строку. Это гарантирует целостность таблицы. Когда мы изучали оператор PRIMARY KEY, то уже видели примеры и мне добавить нечего. Давайте только сведем все вышесказанное, чтобы увидеть свойства первичного ключа:
Ограничение FOREIGN KEY (внешний ключ) гарантирует ссылочную целостность. Ограничение внешнего ключа определяет ссылку на колонку с первичным ключом или уникальную колонку в этой же или другой таблице. С помощью такого ключа обеспечивается целостность связей между таблицами.
Внешний ключ, как и первичный, может состоять из нескольких полей. При создании связующего ключа, количество колонок внешнего ключа должно соответствовать количеству колонок первичного ключа, с которым происходит связь. Кстати, связываться можно не только с первичным ключом, но и с полем, содержащим ограничение уникальности.
Если в связующих таблицах достаточно много строк, то я рекомендую добавить к внешнему ключу еще и индекс. Дело в том, что для внешнего ключа индекс автоматически не создается. Благодаря индексу, сервер сможет быстрее найти связанные строки в разных таблицах.
Ограничение внешнего ключа включает опцию CASCADE, которая позволяет любые изменения сделанные в уникальной колонке или первичном ключе автоматически переносить в значение внешнего ключа. Такое действие называется целостностью каскадных ссылок.
Опция REFERENCE команд CREATE TABLE и ALTER TABLE поддерживаю опции ON DELETE и ON UPDATE. Эти опции позволят вам указать опции CASCADE и NO ACTION:
NO ACTION указывает что любые попытки удалить или обновить ключ, на который ссылается вторичный ключ в другой таблице заканчиваются ошибкой, и изменения откатываются. Это значение по умолчанию и я рекомендую остановиться на нем. Напоминаю, что без особой надобности не стоит включать каскадных действий.
И все же, бывают случаи, когда каскадные действия действительно упрощают программирование, но использовать их нужно очень аккуратно.
1.5.4. Уникальность
Ограничение UNIQUE (уникальность) указывает, что две строки в колонке не могут содержать одно и тоже значение. Это ограничение обеспечивает целостность таблицы с уникальным индексом. Ограничение уникальности эффективно, когда вы уже имеете первичный ключ, но хотите гарантировать, что другое поле тоже уникально.
В отличии от первичного ключа, у уникального поля может быть одна строка с нулевым значением. Это необходимо учитывать и если вы хотите, чтобы поле не могло содержать нулевого значения, добавьте ограничение CHECK, например:
В этом примере создается два ограничения на поле «iID»: одно на уникальность и одно на запрет NULL значений.
Ограничений уникальности может быть несколько в таблице, и для каждого такого поля будет создаваться индекс.
1.5.5. Отключение ограничений
Для повышения производительности, иногда разумно отключить ограничения. Для примера, более эффективно позволить выполнить большую операцию обновления или вставки данных, без ограничений.
Когда вы определяете ограничение на таблицу, которая уже содержит данные, MS SQL Server проверяет данные автоматически, гарантируя, что после создания ограничения, существующие данные соответствуют требованиям.
Отключать можно только ограничения CHECK и FOREIGN KEY. Другие ограничения должны быть удалены и потом снова добавлены.
Для отключения проверки, когда вы добавляете ограничения CHECK и FOREIGN KEY на таблицу с существующими данными, включите опцию WITH NOCHECK в оператор ALTER TABLE.
В следующем примере, мы добавляем ограничение FOREING KEY. Ограничение не проверяет существующие данные на момент добавления ограничения:
Вы можете отключить проверку ограничений на существующие ограничения CHECK и FOREIGN KEY так, что любые данные, которые вы изменяете или добавляете в таблицу, не проверяются с ограничением. Вы можете захотеть отключить проверку ограничений когда:
Включение ограничения, которое было отключено, требует выполнения другого оператора ALTER TABLE, которое содержит опцию CHECK или CHECK ALL.
1.5.5. Роли и объекты значений по умолчанию
Объект по умолчанию и роль – это объекты, которые могут ограничивать одну или несколько полей или типы, определенные пользователем, делая возможным создавать их однажды и использовать регулярно.
Объект по умолчанию работает также как и ограничение, но только этот объект принадлежит базе данных, а не таблице. Если значение не указано, когда вы вставляете данные, для него будет использовано значение по умолчанию объекта, связанного с полем.
Объект значения по умолчанию создается следующим образом:
После создания значения по умолчанию, вы должны связать его с колонкой или типом данных определенным пользователем с помощью вызова системной процедуры sp_bindefault. Для отключения значения по умолчанию выполните системную процедуру sp_unbindefault.
Следующий пример помещает шаблон номера телефона, если не указано реальное значение:
Следующая команда связывает созданный объект с полем «Phone» таблицы TestTable:
Объекты значений по умолчанию имеют свои ограничения:
Теперь переходим к ролям. Роли указывают доступные значения, которые вы можете вставить в колонку. Они гарантируют, что данные подпадают под определенный ряд значений, соответствуют определенному шаблону, или соответствуют определенному списку.
Объявление роли может содержать любые выражения, которые действительны для оператора WHERE, который мы будем внимательно рассматривать в главе 2. В общем виде роль выглядит следующим образом:
После создания роли, вы должны связать его с колонкой или типом данных определенным пользователем с помощью вызова системной процедуры sp_bindrule. Для отключения правила выполните системную процедуру sp_unbinrule. В следующем примере, правило гарантирует, что поле «Pol» может содержать только букву М или Ж:
Следующий пример связывает созданную роль с полем » Pol» таблицы TestTable:
Для удаления значения по умолчанию из базы данных используйте оператор DROP:
Например, созданную ранее роль можно удалить командой:
Правила являются достаточно мощным решением, но при этом они обладают достаточно большим количеством ограничений:
Из-за такого большого количества ограничений для правил, их не очень и хочется использовать. Ограничения намного эффективнее и предоставляют нам больше возможностей. Мало того, что не хочется, корпорация Microsoft сама не рекомендует их использовать, и оставила эту возможность в SQL Server только для совместимости с предыдущими версиями баз данных.
Мы рассмотрели правила потому, что они есть и вы должны о них знать, а может быть, вы найдете им применения, даже не смотря на то, что это не рекомендуется. Но прежде чем вы это сделаете, спешу вас предостеречь. То, что не рекомендуется к использованию производителем и оставлено только для совместимости может больше не появиться в будущих версиях. Это значит, что в следующей версии MS SQL Server правила могут быть выведены из Transact-SQL, и ваша база данных может перестать работать или будет работать без ограничений и потребуются изменения структуры.