Моделирование статистического прогнозирования. Прогнозирование по регрессионной модели
Урок 28. Информатика 11 класс ФГОС

В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет, приобрев в каталоге.
Получите невероятные возможности



Конспект урока «Моделирование статистического прогнозирования. Прогнозирование по регрессионной модели»
На сегодняшнем уроке мы с вами будем учиться прогнозировать по построенной статистической модели. А также выясним, что называется восстановлением значения и для чего используется экстраполяция.
Но прежде, чем приступить к изучению нового материала, давайте повторим некоторые важные моменты нашего прошлого урока.
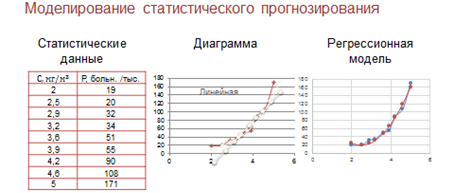
На прошлом занятии мы с вами говорили о моделировании статистического прогнозирования и научились получать математическую модель по медицинским статистическим данным.

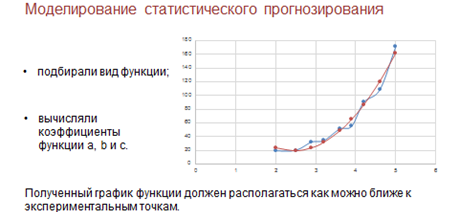
Для того чтобы получить формулу мы сначала по данным, полученным математическими статистами построили диаграмму. Затем подбирали к диаграмме вид функции. Для этого мы рассматривали стандартные функции.
Как вы помните, Полученную таким образом функцию в статистике называют регрессионной моделью.
То есть регрессионная модель – это функция, описывающая зависимость между количественными характеристиками сложных систем.

Затем, после выбора подходящих функций мы подбирали коэффициенты для них. Причём так, чтобы полученный график функции располагался как можно ближе к экспериментальным точкам. Здесь мы применяли метод наименьших квадратов.
По данному методу искомая функция должна быть построена так, чтобы сумма квадратов отклонений игрек-координат всех экспериментальных точек от игрек-координат графика функции была минимальной.
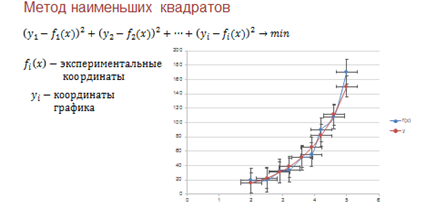
И, таким образом, получили график регрессионной модели, который называется трендом.

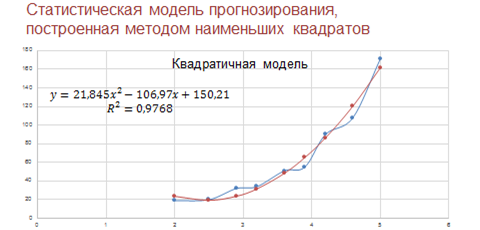
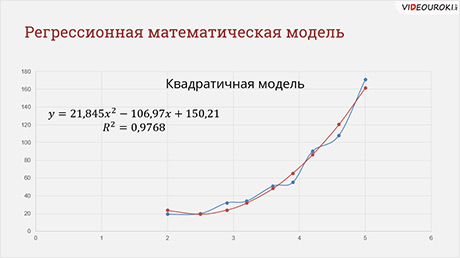
В статистике используется величина Эр в квадрате, которая называется коэффициентом детерминированности, он показывает, насколько удачной является полученная регрессионная модель.

Но для чего мы выполняли все эти построения и вычисления? Для чего нужны такие модели? Ответ на эти и другие вопросы мы получим сегодня на уроке.

Итак, мы получили регрессионную математическую модель по медицинским статистическим данным.
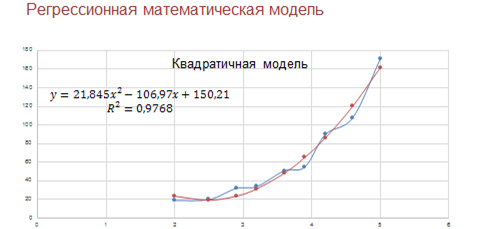
Как вы помните, модель — это объект-заменитель, который в определённых условиях может заменять объект-оригинал. Модель воспроизводит интересующие нас свойства и характеристики оригинала.

То есть наша модель воспроизводит интересующие нас свойства и характеристики, иначе говоря, теперь мы можем прогнозировать процесс путём вычислений.

По данной модели мы можем оценить уровень заболеваемости астмой не только для тех значений концентрации угарного газа, которые были получены экспериментально, но и для других значений.

Построение таких моделей очень важно с практической точки зрения. Если, например, в одном из городов планируется строительство тепловой электростанции, которая является основным источником загрязнения атмосферы, то можно рассчитать вероятную концентрацию угарного газа в воздухе и, соответственно, сделать прогноз на то, как это строительство отразится на здоровье людей.
Есть два способа прогнозирования по регрессионной модели.
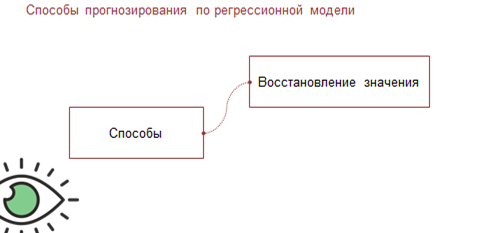
Если прогноз рассчитывается в пределах экспериментальных значений независимой переменной (у нас независимая переменная – это концентрация угарного газа C), то такой прогноз называется восстановлением значения.


Если прогноз рассчитывается за пределами экспериментальных данных. Такой прогноз называется экстраполяцией.

Регрессионную модель просто строить, а затем прогнозировать по ней, с помощью электронных таблиц, например, Microsoft Excel.

На прошлом уроке мы выяснили, что наиболее подходящей является квадратичная зависимость.
Давайте построим электронную таблицу прогнозирования по регрессионной модели первым способом, то есть восстановление значения. Значения независимой переменной будем брать в пределах экспериментальных значений, в нашем случает от двух до пяти.

В ячейку А2 будем вводить значения концентрации угарного газа в промежутке от двух до пяти.
В ячейку Б2 вводим формулу для расчёта числа больных астмой на тысячу жителей. Итак, на прошлом уроке мы получили математическую формулу модели: игрек равно 21 целая 845 тысячных икс в квадрате минус 106 целых 97 сотых икс плюс 150 целых 21 сотая.
Как вы помните ввод формул в Excel начинается со знака равно. Десятичные дроби разделяются запятыми. Для возведения в степень используется знак «шапка».
Протестируем нашу модель. Введём в ячейку А2 значение концентрации угарного газа равное трём. В ячейке Б2 отобразится результат вычислений. Число больных астмой будет равно двадцати пяти целым девятистам пяти тысячным жителя.
Однако считать число людей, даже среднее в дробных величинах нет смысла. Поэтому, нажимаем правой кнопкой мыши на ячейку Б2 и в раскрывшемся меню выберем формат ячеек. В раскрывшемся меню выберем числовые форматы – числовой и в окошке число десятичных знаков, поставим ноль.
Либо на вкладке Главная в разделе число, выбрать формат числовой и три раза нажать на кнопку «Уменьшить разрядность».
Теперь число больных астмой будет равно 26 жителей.
Прогнозирование вторым способом – экстраполяционным производится подобным образом.
Также с помощью табличного процессора Excel можно выполнять экстраполяцию графически. Для этого нужно продолжить тренд, или график регрессионной модели, за пределы экспериментальных данных.
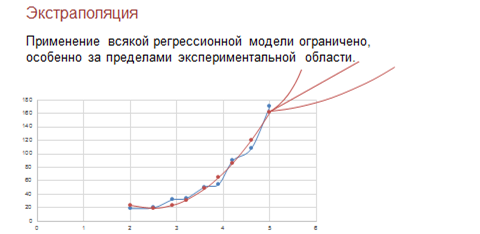
Построим квадратичный тренд для С равного 7. Найдём по графику сколько будет больных астмой, если концентрация угарного газа в воздухе равна 7. Опустим перпендикуляр на ось «Число больных астмой». По графику видно, что число больных приблизительно равно четырёмстам восьмидесяти жителям.
Но бывают случаи, когда экстраполяция может оказаться неправдивой.
Применение всякой регрессионной модели ограничено, особенно за пределами экспериментальной области. В нашем примере при экстраполяции не следует далеко уходить от величины 5 миллиграмм на метр кубический.
Далее характер зависимости может кардинально меняется. Слишком сложной является система «экология — здоровье человека», в ней много различных факторов, которые связаны друг с другом.
Полученная регрессионная функция является всего лишь моделью, где экспериментально подтверждены данные в диапазоне концентраций от 2 до 5 миллиграмм на метр кубический. Что будет вдали от этой области, мы не знаем. Всякая экстраполяция держится на гипотезе: «предположим, что за пределами экспериментальной области закономерность сохраняется». А если не сохраняется?
Квадратичная модель в данном примере в области малых значений концентрации, близких к 0, вообще не годится.

Ведём в нашу таблицу значение концентрации угарного газа 0, получим 150 человек больных астмой, т. е. больше, чем при четырёх миллиграммах на метр кубический. Конечно, это неправда. В области малых значений С лучше работает экспоненциальная модель. Кстати, это довольно типичная ситуация: разным областям данных могут лучше соответствовать разные модели.

А теперь давайте вспомним всё, что мы сегодня изучили на уроке.
По полученной регрессионной модели можно прогнозировать процесс путём вычислений.
Есть два способа прогнозирования по регрессионной модели.
Первый способ. Если прогноз рассчитывается в пределах экспериментальных значений независимой переменной. Такой прогноз называется восстановлением значения.
Второй способ. Если прогноз рассчитывается за пределами экспериментальных данных. Такой прогноз называется экстраполяцией.
Регрессионную модель просто строить, а затем прогнозировать по ней, с помощью электронных таблиц.
В статистическом моделировании регрессионный анализ представляет собой исследования, применяемые с целью оценки взаимосвязи между переменными. Этот математический метод включает в себя множество других методов для моделирования и анализа нескольких переменных, когда основное внимание уделяется взаимосвязи между зависимой переменной и одной или несколькими независимыми. Говоря более конкретно, регрессионный анализ помогает понять, как меняется типичное значение зависимой переменной, если одна из независимых переменных изменяется, в то время как другие независимые переменные остаются фиксированными.

Во всех случаях целевая оценка является функцией независимых переменных и называется функцией регрессии. В регрессионном анализе также представляет интерес характеристика изменения зависимой переменной как функции регрессии, которая может быть описана с помощью распределения вероятностей.
Задачи регрессионного анализа
Данный статистический метод исследования широко используется для прогнозирования, где его использование имеет существенное преимущество, но иногда это может приводить к иллюзии или ложным отношениям, поэтому рекомендуется аккуратно его использовать в указанном вопросе, поскольку, например, корреляция не означает причинно-следственной связи.
Разработано большое число методов для проведения регрессионного анализа, такие как линейная и обычная регрессии по методу наименьших квадратов, которые являются параметрическими. Их суть в том, что функция регрессии определяется в терминах конечного числа неизвестных параметров, которые оцениваются из данных. Непараметрическая регрессия позволяет ее функции лежать в определенном наборе функций, которые могут быть бесконечномерными.
Как статистический метод исследования, регрессионный анализ на практике зависит от формы процесса генерации данных и от того, как он относится к регрессионному подходу. Так как истинная форма процесса данных, генерирующих, как правило, неизвестное число, регрессионный анализ данных часто зависит в некоторой степени от предположений об этом процессе. Эти предположения иногда проверяемы, если имеется достаточное количество доступных данных. Регрессионные модели часто бывают полезны даже тогда, когда предположения умеренно нарушены, хотя они не могут работать с максимальной эффективностью.
В более узком смысле регрессия может относиться конкретно к оценке непрерывных переменных отклика, в отличие от дискретных переменных отклика, используемых в классификации. Случай непрерывной выходной переменной также называют метрической регрессией, чтобы отличить его от связанных с этим проблем.
История

Термин «регресс» придумал Фрэнсис Гальтон в XIX веке, чтобы описать биологическое явление. Суть была в том, что рост потомков от роста предков, как правило, регрессирует вниз к нормальному среднему. Для Гальтона регрессия имела только этот биологический смысл, но позже его работа была продолжена Удни Йолей и Карлом Пирсоном и выведена к более общему статистическому контексту. В работе Йоля и Пирсона совместное распределение переменных отклика и пояснительных считается гауссовым. Это предположение было отвергнуто Фишером в работах 1922 и 1925 годов. Фишер предположил, что условное распределение переменной отклика является гауссовым, но совместное распределение не должны быть таковым. В связи с этим предположение Фишера ближе к формулировке Гаусса 1821 года. До 1970 года иногда уходило до 24 часов, чтобы получить результат регрессионного анализа.

Методы регрессионного анализа продолжают оставаться областью активных исследований. В последние десятилетия новые методы были разработаны для надежной регрессии; регрессии с участием коррелирующих откликов; методы регрессии, вмещающие различные типы недостающих данных; непараметрической регрессии; байесовские методов регрессии; регрессии, в которых переменные прогнозирующих измеряются с ошибкой; регрессии с большей частью предикторов, чем наблюдений, а также причинно-следственных умозаключений с регрессией.
Регрессионные модели
Модели регрессионного анализа включают следующие переменные:
В различных областях науки, где осуществляется применение регрессионного анализа, используются различные термины вместо зависимых и независимых переменных, но во всех случаях регрессионная модель относит Y к функции X и β.
Приближение обычно оформляется в виде E (Y | X) = F (X, β). Для проведения регрессионного анализа должен быть определен вид функции f. Реже она основана на знаниях о взаимосвязи между Y и X, которые не полагаются на данные. Если такое знание недоступно, то выбрана гибкая или удобная форма F.
Зависимая переменная Y
Предположим теперь, что вектор неизвестных параметров β имеет длину k. Для выполнения регрессионного анализа пользователь должен предоставить информацию о зависимой переменной Y:
В последнем случае регрессионный анализ предоставляет инструменты для:
Необходимое количество независимых измерений
Рассмотрим модель регрессии, которая имеет три неизвестных параметра: β0, β1 и β2. Предположим, что экспериментатор выполняет 10 измерений в одном и том же значении независимой переменной вектора X. В этом случае регрессионный анализ не дает уникальный набор значений. Лучшее, что можно сделать, оценить среднее значение и стандартное отклонение зависимой переменной Y. Аналогичным образом измеряя два различных значениях X, можно получить достаточно данных для регрессии с двумя неизвестными, но не для трех и более неизвестных.

Если измерения экспериментатора проводились при трех различных значениях независимой переменной вектора X, то регрессионный анализ обеспечит уникальный набор оценок для трех неизвестных параметров в β.
В случае общей линейной регрессии приведенное выше утверждение эквивалентно требованию, что матрица X Т X обратима.
Статистические допущения
Когда число измерений N больше, чем число неизвестных параметров k и погрешности измерений εi, то, как правило, распространяется затем избыток информации, содержащейся в измерениях, и используется для статистических прогнозов относительно неизвестных параметров. Этот избыток информации называется степенью свободы регрессии.
Основополагающие допущения
Классические предположения для регрессионного анализа включают в себя:
Эти достаточные условия для оценки наименьших квадратов обладают требуемыми свойствами, в частности эти предположения означают, что оценки параметров будут объективными, последовательными и эффективными, в особенности при их учете в классе линейных оценок. Важно отметить, что фактические данные редко удовлетворяют условиям. То есть метод используется, даже если предположения не верны. Вариация из предположений иногда может быть использована в качестве меры, показывающей, насколько эта модель является полезной. Многие из этих допущений могут быть смягчены в более продвинутых методах. Отчеты статистического анализа, как правило, включают в себя анализ тестов по данным выборки и методологии для полезности модели.
Линейный регрессионный анализ
В линейной регрессии особенностью является то, что зависимая переменная, которой является Yi, представляет собой линейную комбинацию параметров. Например, в простой линейной регрессии для моделирования n-точек используется одна независимая переменная, xi, и два параметра, β0 и β1.
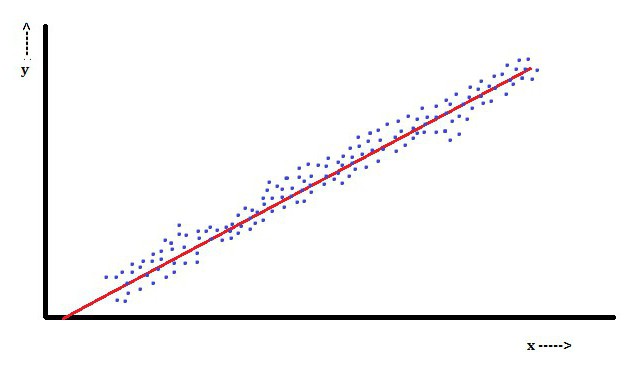
При множественной линейной регрессии существует несколько независимых переменных или их функций.
При случайной выборке из популяции ее параметры позволяют получить образец модели линейной регрессии.
В данном аспекте популярнейшим является метод наименьших квадратов. С помощью него получают оценки параметров, которые минимизируют сумму квадратов остатков. Такого рода минимизация (что характерно именно линейной регрессии) этой функции приводит к набору нормальных уравнений и набору линейных уравнений с параметрами, которые решаются с получением оценок параметров.
При дальнейшем предположении, что ошибка популяции обычно распространяется, исследователь может использовать эти оценки стандартных ошибок для создания доверительных интервалов и проведения проверки гипотез о ее параметрах.
Нелинейный регрессионный анализ
Пример, когда функция не является линейной относительно параметров, указывает на то, что сумма квадратов должна быть сведена к минимуму с помощью итерационной процедуры. Это вносит много осложнений, которые определяют различия между линейными и нелинейными методами наименьших квадратов. Следовательно, и результаты регрессионного анализа при использовании нелинейного метода порой непредсказуемы.
Расчет мощности и объема выборки
Другие методы
Несмотря на то что параметры регрессионной модели, как правило, оцениваются с использованием метода наименьших квадратов, существуют и другие методы, которые используются гораздо реже. К примеру, это следующие методы:
Программное обеспечение
Все основные статистические пакеты программного обеспечения выполняются с помощью наименьших квадратов регрессионного анализа. Простая линейная регрессия и множественный регрессионный анализ могут быть использованы в некоторых приложениях электронных таблиц, а также на некоторых калькуляторах. Хотя многие статистические пакеты программного обеспечения могут выполнять различные типы непараметрической и надежной регрессии, эти методы менее стандартизированы; различные программные пакеты реализуют различные методы. Специализированное регрессионное программное обеспечение было разработано для использования в таких областях как анализ обследования и нейровизуализации.
Русские Блоги
Семь регрессионных моделей
Линейная регрессия и логистическая регрессия обычно являются первыми алгоритмами, с помощью которых люди изучают прогностические модели. Из-за популярности этих двух вариантов многие аналитики считают, что они являются единственной формой регрессии. Ученые, которые знают больше, будут знать, что они являются двумя основными формами всех регрессионных моделей.
Дело в том, что существует множество типов регрессии, и каждый тип регрессии имеет свои конкретные случаи применения. В этой статье я представлю наиболее распространенные модели регрессии в 7 в простой форме. В этой статье я надеюсь помочь вам получить более широкое и всестороннее понимание регрессии, а не просто знать, как использовать линейную регрессию и логистическую регрессию для решения практических задач.
В этой статье в основном будут представлены следующие аспекты:
Что такое регрессионный анализ?
Зачем использовать регрессионный анализ?
Какие бывают виды регрессии?
Полиномиальная регрессия (Полиномиальная регрессия)
Как выбрать подходящую регрессионную модель?
1. Что такое регрессионный анализ?

2. Зачем использовать регрессионный анализ?
Как упоминалось выше, регрессионный анализ может оценить взаимосвязь между двумя или более переменными. Давайте разберемся на простом примере:
Например, вы хотите оценить рост продаж компании на основе текущей экономической ситуации. У вас есть последние данные по компании, и эти данные показывают, что рост продаж примерно в 2,5 раза превышает экономический рост. Используя это понимание, мы можем предсказать будущие продажи компании на основе текущей и прошлой информации.
Использование регрессионных моделей дает множество преимуществ, например:
Выявляет значимую взаимосвязь между зависимыми и независимыми переменными
Выявить степень влияния нескольких независимых переменных на зависимую переменную
Регрессионный анализ также позволяет нам сравнивать влияние переменных, измеряемых в разных масштабах, таких как влияние изменений цен и количество рекламных мероприятий. Преимущество этого заключается в том, что он может помочь исследователям рынка / аналитикам данных / исследователям данных оценить и выбрать лучший набор переменных для построения прогнозных моделей.
3. Какие бывают типы регрессии?
Существует множество методов регрессии, которые можно использовать для прогнозирования. Эти методы регрессии в основном основаны на трех показателях (количество независимых переменных, типы переменных измерения и форма линии регрессии). Мы обсудим это подробно в следующих главах.

Для творческих людей вы можете комбинировать вышеуказанные параметры и даже создавать новые регрессии. Но перед этим рассмотрим наиболее распространенные типы регрессий.
1) Линейная регрессия
Линейная регрессия устанавливает связь между зависимой переменной (Y) и одной или несколькими независимыми переменными (X) с помощью наилучшей прямой линии (также называемой линией регрессии).

Разница между унарной линейной регрессией и множественной линейной регрессией состоит в том, что множественная линейная регрессия имеет более одной независимой переменной, тогда как унарная линейная регрессия имеет только одну независимую переменную. Следующий вопрос: «Как получить наиболее подходящую прямую?»
Как получить наиболее подходящую прямую (определить значения a и b)?


Мы можем использовать индикатор R-квадрат, чтобы оценить производительность модели.
Фокус:
Независимая переменная и зависимая переменная должны соответствовать линейной зависимости.
Множественная регрессия имеет множественную коллинеарность, автокорреляцию и гетероскедастичность.
Линейная регрессия очень чувствительна к выбросам. Выбросы серьезно повлияют на линию регрессии и окончательное прогнозируемое значение.
Мультиколлинеарность увеличивает дисперсию оценок коэффициентов и делает оценки очень чувствительными к небольшим изменениям в модели. В результате оценки коэффициентов нестабильны.
В случае нескольких независимых переменных мы можем использовать методы прямого выбора, обратного исключения и пошагового выбора, чтобы выбрать наиболее важную независимую переменную.
2) Логистическая регрессия
Логистическая регрессия используется для расчета вероятности успеха или неудачи события (неудачи). Когда зависимая переменная является двоичной (0/1, Истина / Ложь, Да / Нет), следует использовать логистическую регрессию. Здесь диапазон значений Y составляет [0,1], что может быть выражено следующим уравнением.
Из-за того, что мы используем биномиальное распределение (зависимая переменная), нам нужно выбрать подходящую функцию активации для отображения вывода между [0,1], и функция Logit соответствует требованиям. В приведенном выше уравнении наилучшие параметры получаются путем использования оценки максимального правдоподобия вместо использования линейной регрессии для минимизации квадратичной ошибки.

Фокус:
Логистическая регрессия широко используется для задач классификации.
Логистическая регрессия не требует линейной связи между зависимой переменной и независимой переменной. Она может обрабатывать несколько типов отношений, поскольку выполняет нелинейное преобразование журнала для предсказанных выходных данных.
Чем больше количество обучающих выборок, тем лучше, потому что, если количество выборок невелико, эффект оценки максимального правдоподобия будет хуже, чем у метода наименьших квадратов.
Независимые переменные не должны коррелироваться, то есть мультиколлинеарность отсутствует. Однако при анализе и моделировании мы можем выбрать включение эффектов взаимодействия категориальных переменных.
Если значение зависимой переменной является порядковым, это называется порядковой логистической регрессией.
Если зависимая переменная является мульти-категориальной, это называется множественной логистической регрессией.
3) Полиномиальная регрессия
В соответствии с уравнением регрессии, если индекс независимой переменной больше 1, то это уравнение полиномиальной регрессии, как показано ниже:
В полиномиальной регрессии наиболее подходящей линией является не прямая линия, а кривая, которая соответствует точкам данных.

Фокус:

Обратите особое внимание на два конца кривой, чтобы увидеть, имеют ли смысл эти формы и тенденции. Полиномы более высокого порядка могут приводить к странным результатам вывода.
4) Пошаговая регрессия
Когда мы имеем дело с несколькими независимыми переменными, используется пошаговая регрессия. В этом методе выбор независимых переменных осуществляется в автоматическом режиме без ручного вмешательства.
Пошаговая регрессия заключается в наблюдении статистических значений, таких как R-квадрат, t-статистика и индикаторы AIC, для определения важных переменных. На основе определенных критериев регрессионная модель постепенно настраивается путем добавления / удаления ковариатов. Распространенные методы пошаговой регрессии следующие:
Стандартная пошаговая регрессия выполняет две функции: на каждом шаге добавляются или удаляются независимые переменные.
Прямой отбор начинается с наиболее важной независимой переменной в модели, а затем на каждом этапе добавляются переменные.
Обратное исключение начинается со всех независимых переменных в модели, а затем на каждом шаге удаляется наименее значимая переменная.
5) Хребтовая регрессия
Ранее мы ввели уравнение линейной регрессии следующим образом:
Это уравнение также имеет погрешность, и полное уравнение может быть выражено как:
Риджевая регрессия решает проблему мультиколлинеарности за счет уменьшения параметра λ (лямбда). Рассмотрим следующее уравнение:

Фокус:
Если не предполагается нормальность, все предположения регрессии гребня и регрессии наименьших квадратов одинаковы.
Регрессия гребня уменьшила значение коэффициента, но не достигла нуля, что указывает на отсутствие функции выбора признаков.
Это метод регуляризации, использующий регуляризацию L2.
6) Регрессия лассо
Подобно гребневой регрессии, штраф за регрессию оператора наименьшей абсолютной усадки и выбора является абсолютным значением коэффициента регрессии. Кроме того, это может уменьшить изменчивость и повысить точность моделей линейной регрессии. Рассмотрим следующее уравнение:

Регрессия лассо отличается от регрессии гребня: функция штрафа использует сумму абсолютных значений коэффициентов вместо квадратов. Это приводит к штрафному члену (или эквиваленту суммы абсолютных значений оценок ограничений), так что некоторые оценки коэффициентов регрессии в точности равны нулю. Чем больше наложенный штраф, тем ближе оценка к нулю. Осознайте, что нужно выбирать из n переменных.
Фокус:
Если не предполагается нормальность, все предположения регрессии лассо и регрессии наименьших квадратов одинаковы.
Регрессия лассо уменьшает коэффициент до нуля (ровно до нуля), что помогает при выборе признаков.
Это метод регуляризации, который использует регуляризацию L1.
Если набор независимых переменных сильно коррелирован, то регрессия лассо выберет только одну из них, а остальные уменьшит до нуля.
7) Эластичная чистая регрессия

Одно из преимуществ взвешивания регрессии гребня и регрессии лассо состоит в том, что оно позволяет эластичной регрессии унаследовать некоторую стабильность регрессии гребня во вращающемся состоянии.
Фокус:
В случае сильно коррелированных переменных он поддерживает групповые эффекты.
Не имеет ограничений на количество выбранных переменных
Он имеет два коэффициента усадки λ1 и λ2.
В дополнение к этим 7 наиболее часто используемым методам регрессии вы также можете изучить другие модели, такие как байесовская, экологическая и робастная регрессия.
4. Как выбрать подходящую регрессионную модель?
Когда вы знаете только одну или две техники, жизнь обычно проста. Одна знакомая мне учебная организация сказала своим студентам: если результат непрерывен, используйте линейную регрессию; если результат двоичный, используйте логистическую регрессию! Однако чем больше вариантов доступно, тем сложнее выбрать правильный ответ. Аналогичная ситуация возникает и при выборе регрессионной модели.
В различных типах регрессионных моделей важно выбрать наиболее подходящий метод, основанный на типах независимых и зависимых переменных, измерениях данных и других существенных характеристиках данных. Вот несколько советов о том, как выбрать подходящую регрессионную модель:
Если набор данных содержит несколько смешанных переменных, вам не следует использовать метод автоматического выбора модели, потому что вы не хотите помещать эти смешанные переменные в модель одновременно.
Это также зависит от ваших целей. По сравнению с моделями с высокой статистической значимостью простые модели легче реализовать.
Вывод:
В этой статье я обсудил 7 типов методов регрессии и ключевые моменты, связанные с каждой регрессией. Как новичок в этой отрасли, я предлагаю вам изучить эти методы и реализовать эти модели в практических приложениях.