Машинное обучение. С чего начать? Часть 1

По мере того, как машинное обучение всё больше внедряют в бизнес-процессы, жизненно важным становится наличие инструмента, который позволяет быстро решать поставленные задачи. Зачастую в качестве такого инструмента выбирают Python. Поэтому, я считаю руководство по Python для машинного обучения будет действительно полезным.
Введение. Машинное обучение с помощью Python
Итак, почему Python? По моему опыту, Python один из самых простых в изучении языков программирования. Data аналитик, не имея глубоких познаний в программировании, должен иметь возможность быстро обрабатывать данные, и Python отлично подходит для этого.
Насколько это сложно?
Это просто. Синтаксис Python имеет больше общего с человеческим языком, чем с машинным. В Python нет надоедливых фигурных скобок, которые только сбивают с толку. Моя коллега из отдела обеспечения качества, которая не имеет отношения к программированию, может написать качественный код на Python в течение дня.
Не удивительно, что Python выбирают создатели библиотек, работы которых в последствии используют специалисты по обработке данных и аналитики для решения своих задач. Далее мы обсудим эти must-have библиотеки для машинного обучения.
Знаменитая библиотека для анализа числовых данных. Она способна на многое: от вычисления медианы распределения данных до обработки многомерных массивов.
2. Pandas
Тот самый инструмент, который поможет вам обрабатывать CSV файлы.
3. Matplotlib
Библиотека для визуализации данных, например дата фреймов Pandas.
4. Seaborn
Так же служит для визуализации, но больше подходит для отображения статистических данных. Например: гистограммы и круговые диаграммы, кривые, корреляционные таблицы.
5. Scikit-Learn
И, наконец, самое главное — библиотека с алгоритмами и другими необходимыми вещами для машинного обучения.
6. Tensorflow и Pytorch
Об этих библиотеках стоит написать отдельный урок. Их используют для так называемого глубокого обучения. Здесь я не буду о них говорить, попробуйте сами разобраться. Оно того стоит.

Проекты
Чтение уроков и повторение упражнений без практики не принесёт должных результатов. Чтобы лучше разобраться в теме, нужно погрузится в реальные данные. Для этого есть платформа, где вы найдёте подходящие проекты по машинному обучению.
Пример проекта, который мы рассмотрим в этом уроке:
Titanic: Machine Learning from Disaster
Речь пойдёт о печально известном «Титанике». Трагическая катастрофа 1912 года, в которой погибли 1502 из 2224 пассажиров и экипажа. В этом конкурсе (или уроке) на основе реальных данных о катастрофе ваша задача предсказать, выжил ли человек во время трагедии.
Урок
Для начала давайте установим необходимые инструменты.
В первую очередь установите сам Python с официального сайта. Чтобы не было проблем с совместимостью библиотек, установите версию 3.6 или выше.
Далее установите все необходимые библиотеки через Python pip. Pip должен установиться автоматически с дистрибутивом Python.
В терминале, командной строке или Powershell введите следующее:
Если вы ещё не знакомы с jupyter notebook, то это популярный инструмент для интерактивного написания кода. Название состоит из слов Julia, Python, и R. Напишите в терминале jupyter notebook, и вам откроется такая страничка:
Наберите код в зелёном поле и сразу увидите результат.
Теперь, когда все инструменты установлены, можно приступать.
Исследование данных
Первым делом нужно изучить данные. Для этого загрузите данные с Kaggle и извлеките их в каталог, в котором вы запустили Jupyter notebook.
Импортируем нужные библиотеки:
Вы должны увидеть такую таблицу:

Это и есть наши данные. Здесь есть следующие колонки:
В процессе изучения данных часто всплывают недостающие данные. Давайте найдём их:
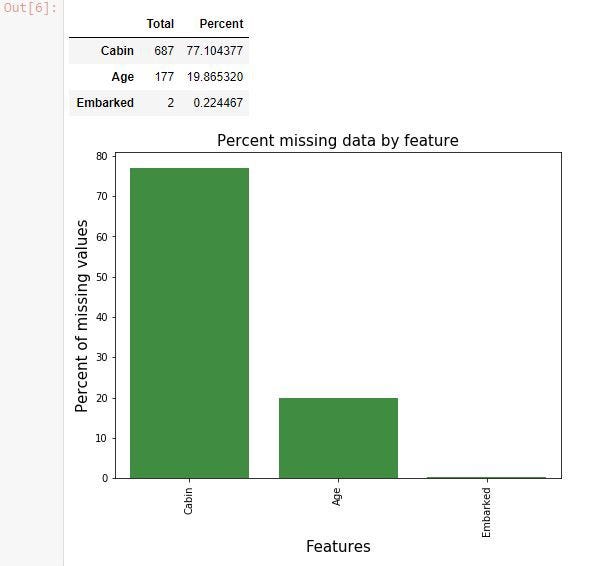
Отсутствуют некоторые значения в колонках Cabin, Age и Embarked. Очень много неизвестных номеров кают. С этим нужно что-то делать. Это называют очисткой данных.
В следующей части мы займёмся чисткой данных от ненужной информации, выявим признаки и построим модель машинного обучения.
Введение в машинное обучение с помощью scikit-learn (перевод документации)
Данная статья представляет собой перевод введения в машинное обучение, представленное на официальном сайте scikit-learn.
В этой части мы поговорим о терминах машинного обучения, которые мы используем для работы с scikit-learn, и приведем простой пример обучения.
Машинное обучение: постановка вопроса
В общем, задача машинного обучения сводится к получению набора выборок данных и, в последствии, к попыткам предсказать свойства неизвестных данных. Если каждый набор данных — это не одиночное число, а например, многомерная сущность (multi-dimensional entry или multivariate data), то он должен иметь несколько признаков или фич.
Обучающая выборка и контрольная выборка
Машинное обучение представляет собой обучение выделению некоторых свойств выборки данных и применение их к новым данным. Вот почему общепринятая практика оценки алгоритма в Машинном обучении — это разбиение данных вручную на два набора данных. Первый из них — это обучающая выборка, на ней изучаются свойства данных. Второй — контрольная выборка, на ней тестируются эти свойства.
Загрузка типовой выборки
Scikit-learn устанавливается вместе с несколькими стандартными выборками данных, например, iris и digits для классификации, и boston house prices dataset для регрессионного анализа.
Например, набор данных digits.data дает доступ к фичам, которые можно использовать для классификации числовых выборок:
а digits.target дает возможность определить в числовой выборке, какой цифре соответствует каждое числовое представление, чему мы и будем обучаться:
Форма массива данных
Обычно, данные представлены в виде двухмерного массива, такую форму имеют n_samples, n_features, хотя исходные данные могут иметь другую форму. В случае с числами, каждая исходная выборка — это представление формой (8, 8), к которому можно получить доступ, используя:
Следующий простой пример с этим набором данных иллюстрирует, как, исходя из поставленной задачи, можно сформировать данные для использования в scikit-learn.
Обучение и прогнозирование
В случае с числовым набором данных цель обучения — это предсказать, принимая во внимание представление данных, какая цифра изображена. У нас есть образцы каждого из десяти возможных классов (числа от 0 до 9), на которым мы обучаем алгоритм оценки (estimator), чтобы он мог предсказать класс, к которому принадлежит неразмеченный образец.
В scikit-learn алгоритм оценки для классификатора — это Python объект, который исполняет методы fit(X, y) и predict(T). Пример алгоритма оценки — это класс sklearn.svm.SVC выполняет классификацию методом опорных векторов. Конструктор алгоритма оценки принимает в качестве аргументов параметры модели, но для сокращения времени, мы будем рассматривать этот алгоритм как черный ящик:
Выбор параметров для модели
В этом примере мы установили значение gamma вручную. Также можно автоматически определить подходящие значения для параметров, используя такие инструменты как grid search и cross validation.
Мы назвали экземпляр нашего алгоритма оценки clf, так как он является классификатором. Теперь он должен быть применен к модели, т.е. он должен обучится на модели. Это осуществляется путем прогона нашей обучающей выборки через метод fit. В качестве обучающей выборки мы можем использовать все представления наших данных, кроме последнего. Мы сделали эту выборку с помощью синтаксиса Python [:-1], что создало новый массив, содержащий все, кроме последней, сущности из digits.data:
Теперь можно предсказать новые значения, в частности, мы можем спросить классификатор, какое число содержится в последнем представлении в наборе данных digits, которое мы не использовали в обучении классификатора:
Соответствующее изображение представлено ниже:

Как вы можете видеть, это сложная задача: представление в плохом разрешении. Вы согласны с классификатором?
Полное решение этой задачи классификации доступно в качестве примера, который вы можете запустить и изучить: Recognizing hand-written digits.
Сохранение модели
В scikit модель можно сохранить, используя встроенный модуль, названный pickle:
В частном случае применения scikit, может быть полезнее заметить pickle на библиотеку joblib (joblib.dump & joblib.load), которая более эффективна для работы с большим объемом данных, но она позволяет сохранять модель только на диске, а не в строке:
Потом можно загрузить сохраненную модель(возможно в другой Python процесс) с помощью:
Обратите внимание, что joblib.dump возвращает список имен файлов. Каждый отдельный массив numpy, содержащийся в clf объекте, сеарилизован как отдельный файл в файловой системе. Все файлы должны находиться в одной папке, когда вы снова загружаете модель с помощью joblib.load.
Обратите внимание, что у pickle есть некоторые проблемы с безопасностью и сопровождением. Для получения более детальной информации о хранении моделей в scikit-learn обратитесь к секции Model persistence.
ПО для машинного обучения на Python

Сегодня существует большое количество программных инструментов для создания моделей Machine Learning. Первые такие инструменты формировались в среде ученых и статистиков, где популярны языки R и Python, исторически сложились экосистемы для обработки, анализа и визуализации данных именно на этих языках, хотя определенные библиотеки машинного обучения есть и для Java, Lua, С++. При этом интерпретируемые языки программирования существенно медленнее компилируемых, поэтому на интерпретируемом языке описывают подготовку данных и структуру моделей, а основные вычисления проводят на компилируемом языке.
В данном посте мы расскажем преимущественно о библиотеках, имеющих реализацию на Python, поскольку этот язык обладает большим количеством пакетов для интеграции в разного рода сервисы и системы, а также для написания различных информационных систем. Материал содержит общее описание известных библиотек и будет полезен прежде всего тем, кто начинает изучать область ML и хочет примерно понимать, где искать реализации тех или иных методов.
При выборе конкретных пакетов для решения задач в первую очередь стоит определиться, заложен ли в них механизм для решения ваших проблем. Так, например, для анализа изображений, скорее всего, придется иметь дело с нейронными сетями, а для работы с текстом — с рекурентными, при небольшом количестве данных от нейросетей наверняка придется отказаться.
Библиотеки общего назначения на Python
Все описанные в данном разделе пакеты так или иначе используются при решении практически любой задачи по машинному обучению. Часто их достаточно, чтобы построить модель целиком, по крайней мере в первом приближении.
NumPy
Библиотека с открытым исходным кодом для выполнения операций линейной алгебры и численных преобразований. Как правило, такие операции необходимы для преобразования датасетов, которые можно представить в виде матрицы. В библиотеке реализовано большое количество операций для работы с многомерными массивами, преобразования Фурье и генераторы случайных чисел. Форматы хранения numpy де-факто являются стандартом для хранения числовых данных во многих других библиотеках (например, Pandas, Scikit-learn, SciPy).
Pandas
Библиотека для обработки данных. С ее помощью можно загрузить данные практически из любого источника (интеграция с основными форматами хранения данных для машинного обучения), вычислить различные функции и создать новые параметры, построение запросов к данным с помощью агрегативных функций сродни реализованным в SQL. Кроме того, имеются разнообразные функции преобразования матриц, метод скользящего окна и прочие методы для получения информации из данных.
Scikit-learn
Библиотека программного обеспечения с более чем десятилетней историей содержит реализации практически всех возможных преобразований, и нередко ее одной хватает для полной реализации модели. Как правило, при программировании практически любой модели на языке Python какие-то преобразования с использованием данной библиотеки всегда присутствуют.
Scikit-learn содержит методы разбиения датасета на тестовый и обучающий, вычисление основных метрик над наборами данных, проведение кросс-валидации. В библиотеке также есть основные алгоритмы машинного обучения: линейной регрессии (и ее модификаций Лассо, гребневой регрессии), опорных векторов, решающих деревьев и лесов и др. Есть и реализации основных методов кластеризации. Кроме того, библиотека содержит постоянно используемые исследователями методы работы с параметрами (фичами): например, понижение размерности методом главных компонент. Частью пакета является библиотека imblearn, позволяющая работать с разбалансированными выборками и генерировать новые значения.
SciPy
Довольно обширная библиотека, предназначенная для проведения научных исследований. В ее состав входит большой набор функций из математического анализа, в том числе вычисление интегралов, поиск максимума и минимума, функции обработки сигналов и изображений. Во многих отношениях данную библиотеку можно считать аналогом пакета MATLAB для разработчиков на языке Python. C ее помощью можно решать системы уравнений, использовать генетические алгоритмы, выполнять многие задачи по оптимизации.
Специфические библиотеки
В данном разделе рассмотрены библиотеки или со специфической сферой применимости, или популярные у ограниченного числа пользователей.
Tensorflow
Библиотека, разработанная корпорацией Google для работы с тензорами, используется для построения нейросетей. Поддержка вычислений на видеокартах имеет версию для языка C++. На основе данной библиотеки строятся более высокоуровневые библиотеки для работы с нейронными сетями на уровне целых слоев. Так, некоторое время назад популярная библиотека Keras стала использовать Tensorflow как основной бэкенд для вычислений вместо аналогичной библиотеки Theano. Для работы на видеокартах NVIDIA используется библиотека cuDNN. Если вы работаете с картинками (со сверточными нейросетями), скорее всего, придется использовать данную библиотеку.
Keras
Библиотека для построения нейросетей, поддерживающая основные виды слоев и структурные элементы. Поддерживает как рекуррентные, так и сверточные нейросети, имеет в своем составе реализацию известных архитектур нейросетей (например, VGG16). Некоторое время назад слои из данной библиотеки стали доступны внутри библиотеки Tensorflow. Существуют готовые функции для работы с изображениями и текстом (Embedding слов и т.д.). Интегрирована в Apache Spark с помощью дистрибутива dist-keras.
Caffe
Фреймворк для обучения нейросетей от университета Беркли. Как и TensorFlow, использует cuDNN для работы с видеокартами NVIDIA. Содержит в себе реализацию большего количества известных нейросетей, один из первых фреймворков, интегрированных в Apache Spark (CaffeOnSpark).
pyTorch
Позволяет портировать на язык Python библиотеку Torch для языка Lua. Содержит реализации алгоритмов работы с изображениями, статистических операций и инструментов работы с нейронными сетями. Отдельно можно создать набор инструментов для оптимизационных алгоритмов (в частности стохастического градиентного спуска).
Реализации градиентного бустинга над решающими деревьями
Подобные алгоритмы неизменно вызывают повышенный интерес, так как часто они показывают лучший результат, чем нейросети. Особенно это проявляется, если в вашем распоряжении не очень большие наборы данных (очень грубая оценка: тысячи и десятки тысяч, но не десятки миллионов). Среди моделей-победителей на соревновательной платформе kaggle алгоритмы градиентного бустинга над решающими деревьями встречаются довольно часто.
Как правило, реализации таких алгоритмов есть в библиотеках машинного обучения широкого профиля (например, в Scikit-learn). Однако существуют особые реализации данного алгоритма, которые часто можно встретить среди победителей различных конкурсов. Стоит выделить следующие.
Xgboost
Самая распространенная реализация градиентного бустинга. Появившись в 2014 г., уже к 2016-му она завоевала немалую популярность. Для выбора разбиения используют сортировку и модели, основанные на анализе гистограмм.
LightGBM
CatBoost
Разработка компании Яндекс, вышедшая, как и LightGBM, в 2017 г. Реализует особый подход к обработке категориальных признаков (основанный на target encoding, т.е. на подмене категориальных признаков статистиками на основе предсказываемого значения). К тому же алгоритм содержит особый подход к построению дерева, который показал лучшие результаты. Проведенное нами сравнение показало, что данный алгоритм лучше других работает прямо «из коробки», т.е. без настройки каких-либо параметров.
Microsoft Cognitive Toolkit (CNTK)
Другие ресурсы для разработки
По мере популяризации машинного обучения неоднократно появлялись проекты по упрощению разработки и приведению его в графическую форму с доступом через онлайн. В данном поле можно отметить несколько.
Azure ML
Сервис машинного обучения на платформе Microsoft Azure, в котором можно выстраивать обработку данных в виде граф и проводить вычисления на удаленных серверах, с возможностью включения кода на языке Python и на других.
IBM DataScience experience (IBM DSX)
Сервис для работы в среде Jupyter Notebook с возможностью выполнять вычисления в языке Python и на других. Поддерживает интеграцию с известными наборами данных и Spark, проектом IBM Watson.
Пакеты для социальных наук
Среди них можно выделить IBM Statistical Package for the Social Sciences (SPSS) — программный продукт IBM для обработки статистики в социальных науках, поддерживает графический интерфейс задания процесса обработки данных. Некоторое время назад стало можно встраивать алгоритмы машинного обучения в общую структуру выполнения. В целом, ограниченная поддержка алгоритмов машинного обучения становится популярной среди пакетов для статистиков, в которых уже включены статистические функции и методы визуализации (например, Tableau и SAS).
Заключение
Выбор программного пакета, на основе которого будет решаться задача, обычно определяется следующими условиями.
Построить первую модель можно, используя сравнительно небольшое число библиотек, а дальше придется принимать решение, на что тратить время: на проработку параметров (feature engineering) или на подбор оптимальной библиотеки и алгоритма, или же выполнять эти задачи параллельно.
Теперь немного о рекомендациях по выбору. Если вам нужен алгоритм, который лучше всего работает прямо «из коробки», — это Catboost. Если вы предполагаете работать с изображениями, можно использовать Keras и Tensorflow или Caffe. При работе с текстом надо определиться, собираетесь ли вы строить нейросеть и учитывать контекст. Если да, те же пожелания, что и к изображениям, если достаточно «мешка слов» (частотных характеристик встречаемости каждого слова), подойдут алгоритмы градиентного бустинга. При небольших наборах данных можно использовать алгоритмы генерации новых данных из Scikit-learn и линейные методы, реализованные в той же библиотеке.
Как правило, описанных библиотек хватает для решения большинства задач, даже для победы на соревнованиях. Область машинного обучения развивается очень быстро — мы уверены, что новые фреймворки появились уже в момент написания этого поста.
Николай Князев, руководитель группы машинного обучения «Инфосистемы Джет»
Руководство для начинающих по машинному обучению на Python

Если вы новичок, вы не знаете, с чего начать обучение и зачем вам машинное обучение, и почему оно приобретает все большую популярность в последнее время, вы попали в нужное место! Я собрал всю необходимую информацию и полезные ресурсы, чтобы помочь вам получить новые знания и выполнить ваши первые проекты.
Зачем начинать с Python?
Если ваша цель превращается в успешного программиста, вам нужно знать много вещей. Но для машинного обучения и науки о данных вполне достаточно освоить хотя бы один язык программирования и уверенно использовать его. Итак, успокойся, тебе не нужно быть гением программирования.
Для успешного обучения машинному обучению необходимо выбрать подходящий язык кодирования с самого начала, так как ваш выбор определит ваше будущее. На этом этапе вы должны продумать стратегически и правильно расставить приоритеты и не тратить время на ненужные вещи.
Мое мнение — Python является идеальным выбором для начинающих, чтобы сосредоточиться на том, чтобы перейти в области машинного обучения и науки о данных. Это минималистичный и интуитивно понятный язык с полнофункциональной библиотечной линией (также называемой фреймворками), которая значительно сокращает время, необходимое для получения первых результатов.
Шаг 0. Краткий обзор процесса ML, который вы должны знать

Машинное обучение — это обучение, основанное на опыте. Например, это похоже на человека, который учится играть в шахматы через наблюдение, как играют другие. Таким образом, компьютеры могут быть запрограммированы путем предоставления информации, которую они обучают, приобретая способность идентифицировать элементы или их характеристики с высокой вероятностью.
Прежде всего, вам необходимо знать, что существуют различные этапы машинного обучения :
Для поиска шаблонов используются различные алгоритмы, которые делятся на две группы :
При неконтролируемом обучении ваша машина получает только набор входных данных. После этого аппарат включается, чтобы определить взаимосвязь между введенными данными и любыми другими гипотетическими данными. В отличие от контролируемого обучения, когда машина снабжена некоторыми проверочными данными для обучения, независимое неконтролируемое обучение подразумевает, что сам компьютер найдет шаблоны и взаимосвязи между различными наборами данных. Самостоятельное обучение можно разделить на кластеризацию и ассоциацию.
Контролируемое обучение подразумевает способность компьютера распознавать элементы на основе предоставленных образцов. Компьютер изучает его и развивает способность распознавать новые данные на основе этих данных. Например, вы можете настроить свой компьютер для фильтрации спам-сообщений на основе ранее полученной информации.
Некоторые контролируемые алгоритмы обучения включают в себя:
Шаг 1. Уточните свои математические навыки, необходимые для математических библиотек Python
Человек, работающий в области ИИ и МЛ, который не знает математику, похож на политика, который не умеет убеждать. У обоих есть неизбежная область для работы!
Так что да, вы не можете иметь дело с проектами ML и Data Science без минимальной математической базы знаний. Тем не менее, вам не нужно иметь степень по математике, чтобы преуспеть. По моему личному опыту, посвящение по крайней мере 30–45 минут каждый день принесет много пользы, и вы быстрее поймете и изучите продвинутые темы Python для математики и статистики.
Вот 3 шага для изучения математики, необходимой для анализа и машинного обучения:
1 — Линейная алгебра для анализа данных: скаляры, векторы, матрицы и тензоры
Например, для метода главных компонентов вам нужно знать собственные векторы, а регрессия требует умножения матриц. Кроме того, машинное обучение часто работает с многомерными данными (данными со многими переменными). Этот тип данных лучше всего представлен матрицами.
2 — Математический анализ: производные и градиенты
Математический анализ лежит в основе многих алгоритмов машинного обучения. Производные и градиенты будут необходимы для задач оптимизации. Например, одним из наиболее распространенных методов оптимизации является градиентный спуск.
Для быстрого изучения линейной алгебры и математического анализа я бы порекомендовал следующие курсы:
Хан Академия предлагает короткие практические занятия по линейной алгебре и математическому анализу. Они охватывают самые важные темы.
MIT OpenCourseWare предлагает отличные курсы для изучения математики для ML. Все видео лекции и учебные материалы включены.
3 — градиентный спуск: построение простой нейронной сети с нуля

Одним из лучших способов изучения математики в области анализа и машинного обучения является создание простой нейронной сети с нуля. Вы будете использовать линейную алгебру для представления сети и математический анализ для ее оптимизации. В частности, вы создадите градиентный спуск с нуля. Не стоит слишком беспокоиться о нюансах нейронных сетей. Это хорошо, если вы просто следуете инструкциям и пишете код.
Вот несколько хороших прохождений:
Короткие учебники, которые также помогут вам шаг за шагом освоить нейронные сети:
Шаг 2. Изучите основы синтаксиса Python
Хорошие новости: вам не нужен полный курс обучения, так как Python и анализ данных не являются синонимами.

Прежде чем начать углубляться в синтаксис, я хочу поделиться одним проницательным советом, который может свести к минимуму ваши возможные сбои.
Научиться плавать, читая книги по технике плавания, невозможно, но чтение их параллельно с тренировками в бассейне приводит к более эффективному приобретению навыков.
Аналогичное действие происходит при изучении программирования. Не стоит фокусироваться исключительно на синтаксисе. Просто так вы рискуете потерять интерес.
Вам не нужно запоминать все. Делайте маленькие шаги и не бойтесь совмещать теоретические знания с практикой. Сосредоточьтесь на интуитивном понимании, например, какая функция подходит в конкретном случае и как работают условные операторы. Вы будете постепенно запоминать синтаксис, читая документацию и в процессе написания кода. Вскоре вам больше не придется гуглить такие вещи.
Вот еще несколько полезных ресурсов для изучения:
И помните: чем раньше вы начнете работать над реальными проектами, тем раньше вы это освоите. В любом случае, вы всегда можете вернуться к синтаксису, если вам это нужно.
Шаг 3. Откройте для себя основные библиотеки анализа данных

Дальнейшим этапом является пересмотр и добавление части Python, которая применима к науке о данных. И да, пора изучать библиотеки или фреймворки. Как указывалось ранее, Python обладает огромным количеством библиотек. Библиотеки — это просто набор готовых функций и объектов, которые вы можете импортировать в свой скрипт, чтобы тратить меньше времени.
Как использовать библиотеки? Вот мои рекомендации:
Я не рекомендую немедленно погружаться в изучение библиотек, потому что вы, вероятно, забудете большую часть того, что узнали, когда начнете использовать их в проектах. Вместо этого попытайтесь выяснить, на что способна каждая библиотека.
Библиотеки Python, которые вам понадобятся:
NumPy
NumPy сокращен от Numeric Python, это самая универсальная и универсальная библиотека как для профессионалов, так и для начинающих. Используя этот инструмент, вы сможете легко и комфортно работать с многомерными массивами и матрицами. Такие функции, как операции линейной алгебры и числовые преобразования также доступны.
Pandas
Pandas — это хорошо известный и высокопроизводительный инструмент для представления кадров данных. С его помощью вы можете загружать данные практически из любого источника, вычислять различные функции и создавать новые параметры, создавать запросы к данным с использованием агрегатных функций, похожих на SQL. Более того, существуют различные функции преобразования матриц, метод скользящего окна и другие методы получения информации из данных. Так что это совершенно незаменимая вещь в арсенале хорошего специалиста.
Matplotlib
Matplotlib — это гибкая библиотека для создания графиков и визуализации. Это мощный, но несколько тяжелый вес. На этом этапе вы можете пропустить Matplotlib и использовать Seaborn для начала работы (см. Seaborn ниже).
Scikit-Learn
Я могу сказать, что это самый хорошо разработанный пакет ML, который я когда-либо наблюдал. Он реализует широкий спектр алгоритмов машинного обучения и позволяет использовать их в реальных приложениях. Здесь вы можете использовать целый ряд функций, таких как регрессия, кластеризация, выбор модели, предварительная обработка, классификация и многое другое. Так что это абсолютно стоит изучить и использовать. Большим преимуществом здесь является высокая скорость работы. Поэтому неудивительно, что такие ведущие платформы, как Spotify, Booking.com, JPMorgan, используют scikit-learn.
Шаг 4. Разработка структурированных проектов
Как только вы освоите базовый синтаксис и изучите основы библиотек, вы уже можете начать создавать проекты самостоятельно. Благодаря этим проектам вы сможете узнавать о новых вещах, а также создавать портфолио для дальнейшего поиска работы.
Есть достаточно ресурсов, которые предлагают темы для структурированных проектов.
Шаг 5. Работа над собственными проектами
Вы можете найти много нового, но важно найти те проекты, которые пробудят в вас свет. Однако прямо перед этим счастливым моментом поиска работы своей мечты вы должны научиться превосходно обрабатывать ошибки в своих программах. Среди наиболее популярных полезных ресурсов для этой цели можно выделить следующие:
Последнее слово и немного мотивации
Вы, возможно, спросите: «Почему я должен погрузиться в сферу машинного обучения? возможно, уже есть много других хороших специалистов.
Знаешь что? Я тоже попал в эту ловушку и теперь смело могу сказать — такое мышление не принесет вам ничего хорошего. Это огромный барьер для вашего успеха.
Согласно закону Мура число транзисторов в интегральной схеме удваивается каждые 24 месяца. Это означает, что с каждым годом производительность наших компьютеров растет, а это означает, что ранее недоступные границы знаний снова «сдвигаются вправо» — есть место для изучения больших данных и алгоритмов машинного обучения!
Кто знает, что нас ждет в будущем. Возможно, эти цифры увеличатся еще больше, и машинное обучение станет более важным? И, скорее всего, да!
Чувак, самое ужасное, что ты можешь сделать, это предположить, что твое место уже занято другим специалистом.